
Deterministic Agents: The Facts, Mythology, and Mirage About Tool Counts
Tools are not advanced prompt engineering; the blossoming revolt against agent creativity; a scientific framework for understanding the tradeoff.

Have you ever encountered this dichotomy?
Your LinkedIn is filled with statements like this: “My agent automatically saved me $500 a month in household expenses. I provided tools to renegotiate my monthly vendor expenses and it just autonomously…”
But at the same time you open your Slack to the murmurred words of caution from our colleagues: “Be careful with your tool counts… it may lead to hallucination.”
What gives?
This bothered me.
The obvious tension between creativity (the ability for the agent to achieve a wide variety of tasks), consistency and predictability (the ability for an agent to achieve a consistent outcome), and token and reasoning expenses seems to be a side thought that is anecdotally handled by the industry. It is chalked up to be a derivation of prompt engineering.
A couple of weeks ago I started to think about a mathematical model for this problem. I would like to now walk you through this model.
Come along for an information theory ride.
Here is something every person who has ever built an AI agent has discovered, usually around 2 a.m., usually by accident.

You give the thing a few tools and it behaves. You give it a few more and it gets clever. You give it a lot more and it gets — weird. Flaky. It does the right thing on Tuesday and a slightly unhinged thing on Wednesday, same prompt, same model, same temperature, same phase of the moon. And the diagnosis, whispered in every engineering Slack on earth, is always identical:
Too many tools. The model's overwhelmed. Cut some.
It is a reasonable instinct. It is also, mostly, wrong. And underneath the whole mess is a hard limit — a wall you keep running into — that, once you see it clearly, you realize you cannot engineer your way around. You can only choose where it hurts.
Let me walk you through it, because once you see it you can’t unsee it, and you’ll be a better builder for the rest of your career.
First, count destinations, not roads
The whole thing turns on one move, and if you get the move you get all of it.
Stop counting what your agent does. Start counting where it ends up.
Waze can route you to the same coffee shop three different ways. That is not three outcomes. That is one coffee and three opinions about traffic. If you’re trying to reason about whether your agent is reliable, the roads it took don’t matter — the destination does.
Two trajectories that land in the same end-state are one outcome, full stop.
This sounds like a pedantic bookkeeping choice. It is the opposite. The instant you count outcomes instead of actions, the entire messy behavior of an agent collapses into a clean accounting problem — and clean accounting problems have hard laws hiding in them.
However, reasoning chains are quite interesting for debugging agents. I routinely use (and store) them to optimize latency and also as a leading indicator of where an agent is going off the rails. But this never is more important than the actual outcome. Tunnel vision can lead to over optimization of reasoning chains at the expense of quality, deterministic, outcomes.
The budget that always balances
Here’s the accounting. Take everything your tools can possibly reach — every distinct end-state the surface can produce. Call the size of that set S, the reachable variety. It’s the ceiling on how interesting your agent could ever be.
Now: every bit of that variety has to land in exactly one of three buckets.
The first bucket is I — the variety your task actually steers. You asked for the quarterly summary and you got the quarterly summary. Knowing the task told you the outcome. This is the good bucket. This is the whole reason you built the thing.
The second bucket is N — the variety that shows up run to run, with the task held fixed. You asked the same question twice and got two different answers. This is nondeterminism. This is the 2 a.m. bucket.
The third bucket is U — variety that’s reachable in principle but never actually happens. Capability you shipped and never lit up. The tool that’s been in the manifest for six months and has been called precisely zero times. Call it collapse, or call it waste; the math doesn’t care about your feelings.
And here’s the law — the part that isn’t a metaphor, it’s an identity — they sum:
S = I + N + U.
Always. No remainder, no rounding error, no clever architecture that makes the right-hand side smaller than the left. It’s a budget. And like every honest budget, the depressing thing about it is that it balances. You cannot conjure more total variety by wishing. You can only move it between buckets — and as we’re about to see, you don’t even get to do that for free.
The wall
Now the ceiling.
There is a hard cap on how big bucket I can ever get. I’ll call it κ — the routing capacity of your task-to-outcome channel. It is, and I love this, the exact same quantity Claude Shannon defined in 1948 to tell you how much information you can cram down a telephone line.
Side note, I have a real-time communication background, this allegory is not an accident.
Your task is the signal. Your agent’s outcome is what comes out the other end. κ is the most faithful steering that channel can possibly support, over the best workload you could ever feed it.
This is not a new law of nature. It’s a very old one wearing a startup hoodie.
And here’s the wall. If your reachable variety S is bigger than your routing capacity κ, then the surplus — the amount by which S exceeds κ — has nowhere to live except buckets N and U. You built more variety than the channel can faithfully route, and the leftover doesn’t evaporate. It has to come out somewhere. So it comes out as noise (your agent gets flaky) or as collapse (your agent quietly ignores half its toolbox). Usually both.
Write it however you like; the inequality is N + U ≥ S − κ. In English: whatever you build above capacity, you pay for in irreproducibility or in waste. There’s no third option. You can’t pay it down by being a better engineer, any more than you can ship a 4G signal down a wet shoelace by writing tighter code.
That’s the κ-Wall.
The trilemma (or: the part that should be on a T-shirt)
Stack those two facts and you get the cruel little rule at the center of all this:
Above capacity, you cannot have an agent that is simultaneously fully utilized, reliably routed, and deterministic. Pick at most two.
Want every tool used and rock-solid reproducibility? Then your task can’t actually be steering all of it — your routing is leaky. Want full utilization and tight routing? Enjoy your nondeterminism. Want determinism and tight routing above capacity? Fine — but then you’re sitting on capability you never touch, and you could’ve shipped a simpler thing.
There is no free tool.
Every bit of expressivity you add above the wall is purchased with one of the other two currencies, and the universe always collects.

Two ways it goes wrong, and they look nothing alike
The genuinely useful move is to separate the symptoms, because the same wall presents as two completely different bugs and most teams only know how to recognize one of them.
In noise mode, the surplus pours into N. Your agent is busy, ambitious, calls everything, and is maddeningly inconsistent. You’ll notice this one, because it files bug reports about itself.
In collapse mode, the surplus pours into U. Your agent is calm, reliable, and quietly using a third of what you gave it while you pay for the documentation, the maintenance, and the context window of the rest. You will not notice this one for months, because nothing is on fire. It just isn’t as good as it could be, and nobody can say why.
Same wall. Same surplus. Two faces. And you can dial the channel between them like a mixing board — degrade the channel and watch the surplus turn into pure noise; restrict what gets used and watch it turn into pure waste — every point along the way obeying the budget. Conservation isn’t a vibe. It holds to the decimal.
I would place a bet that ~95% of agents today are in collapse mode. This is yet another reason that 95% of enterprise AI projects are failing. They are not laser focused on the outcome and are rather getting dazzled by non-deterministic creativity.
So here is the lever everyone is pulling, and it’s the wrong one
“Cut the number of tools.”
Wrong lever. I’ll say it louder for the platform teams in the back: the count is not your problem.
Cutting tools at random to fix this is like fixing a dysfunctional group chat by removing people at random. Sometimes you get lucky and remove the guy who only sends GIFs. Usually you remove the one person who actually knew where the dinner reservation was, and now the chat is smaller and useless.
What actually drives the wall down — what actually shrinks κ — is two things, and neither is headcount.
The first is overlap. Confusability. Two tools that do almost-the-same-thing are quiet poison. It was never the length of the Cheesecake Factory menu that hurt you; it was that fourteen of the entrées are the same chicken with a different adjective, and now you can’t choose and neither can the model.
Your phone’s autocorrect doesn’t fumble because the dictionary is big. It fumbles because “their,” “there,” and “they’re” all sound like the same thing to a machine doing its best at 3 a.m.

Build two tools that sound like the same thing and you’ve manufactured your own nondeterminism.
The second is forced composition depth — how many tool calls you make the model chain together before it can reach an outcome. Every forced hop is another place for the signal to smear.
So the real moves are the boring, honest ones.
Raise κ: disambiguate the tools that overlap, dedupe the redundant ones, put a retrieval layer in front so the model isn’t squinting at all fifty options at once, or reach for a stronger model.
Or lower S: coarsen the surface, build a few apt macros instead of a thousand fiddly primitives, and stop forcing six-step chains where two would do.
Cutting tools only helps to the exact extent that the tools you cut were the overlapping ones — and if that’s true, just say that, and cut those.
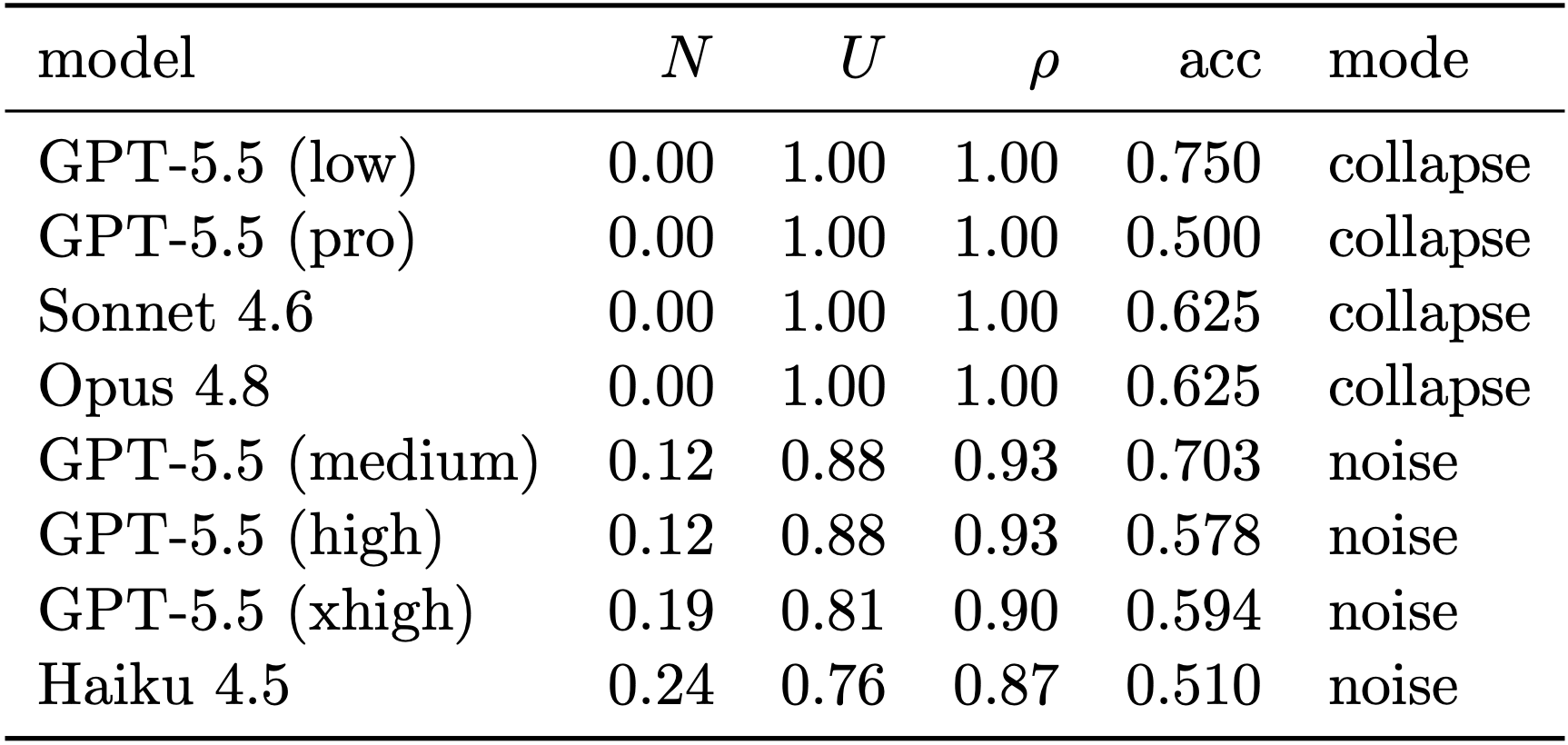
And it isn’t just theory
So I built the instrument and pointed it at real, shipping models — Haiku, Sonnet, Opus, and GPT-5.5 — and made them route through tool surfaces engineered to overlap more and more as they grew. I didn’t assume determinism. I measured it, running every intent fifteen times and counting how often the same answer came back.
Start with the cleanest case. Hand Claude Haiku 4.5 four tools, then eight, then twelve — all genuinely distinct — and it routes perfectly.
Capacity climbs right alongside the ideal line, accuracy sits at 100%, run-to-run nondeterminism is flat zero.
Then push to sixteen tools where the last four are deliberate near-twins of earlier ones — a “filter” that shadows a “where-clause,” a “dedupe” that shadows a “distinct” — and the ceiling bends.
Capacity stalls below where it should be, accuracy slips to 92%, and nondeterminism shows up for the first time, materializing exactly where the wall said it had to. The model did not get dumber between tool twelve and tool sixteen. The surface got ambiguous, and the surplus had to land somewhere.

And before anyone emails me: if you’ve run the same agent twice, gotten two different answers, and quietly blamed yourself — it wasn’t you. Production models don’t even expose a random seed, temperature zero was never a promise of reproducibility, and the only honest move is to measure how often the same answer actually comes back. Almost nobody does.
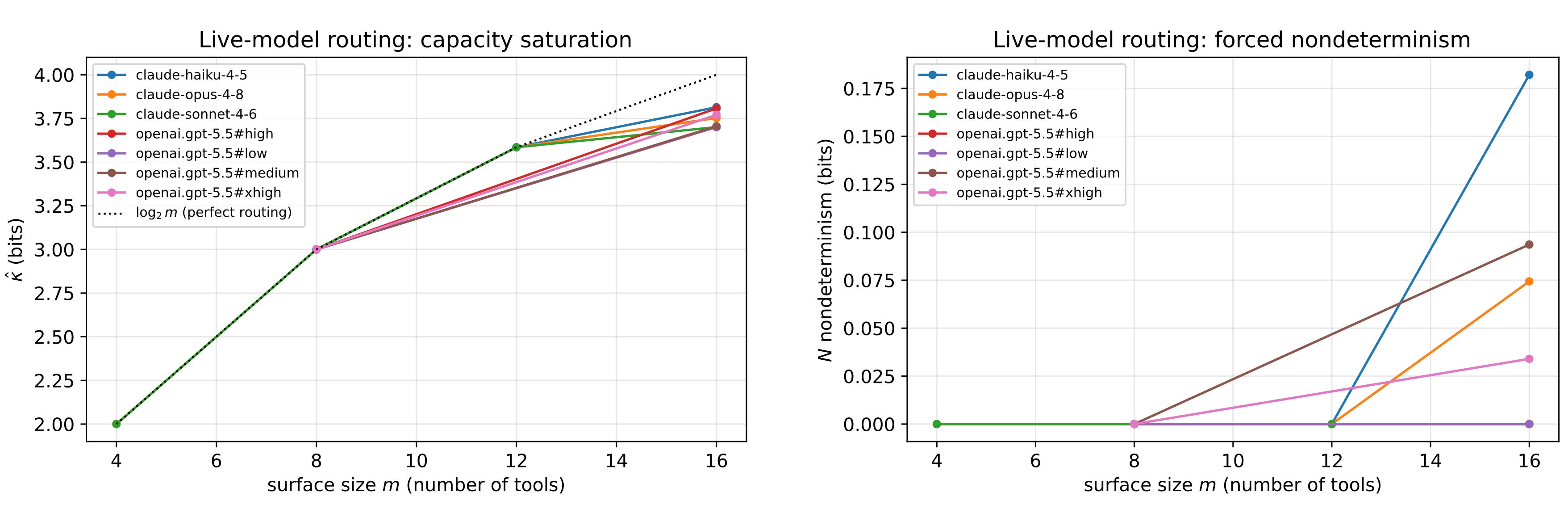
Now the part that surprised even me. The wall is democratic. Every model I tested hits it in the same neighborhood — capacity flattening out around 3.7 to 3.8 bits, call it roughly fourteen tools a frontier model can actually tell apart.
What is not democratic is the currency each one pays the surplus in. Remember the two failure modes? Here they are, in the wild.
Haiku paid in noise — it got a little twitchy. Sonnet, and GPT-5.5 on its lower reasoning setting, paid in pure collapse — dead calm, perfectly repeatable, and quietly consolidating onto fewer tools than they were handed. Opus split the difference.
Here is the sentence I want every platform team to tape to a monitor.
Sonnet’s repeatability came back a perfect 1.0 — and its accuracy fell to 81%.
It was reliably, confidently, reproducibly routing to the wrong tool, shrinking its own toolbox as it went.
If you had been watching only the thing everyone watches — flakiness, run-to-run jitter — you would have seen that flawless 1.0, signed off, and shipped. The third bucket doesn’t make noise. That is exactly what makes it dangerous.
A monitor that only catches nondeterminism will hand a gold star to an agent that has silently stopped using half of what you built.
This also has a profound implication on the seemingly common corporate strategy of: “let’s just have every employee use ChatGPT and arm it with dozens of tools.”
The wall with its clothes off
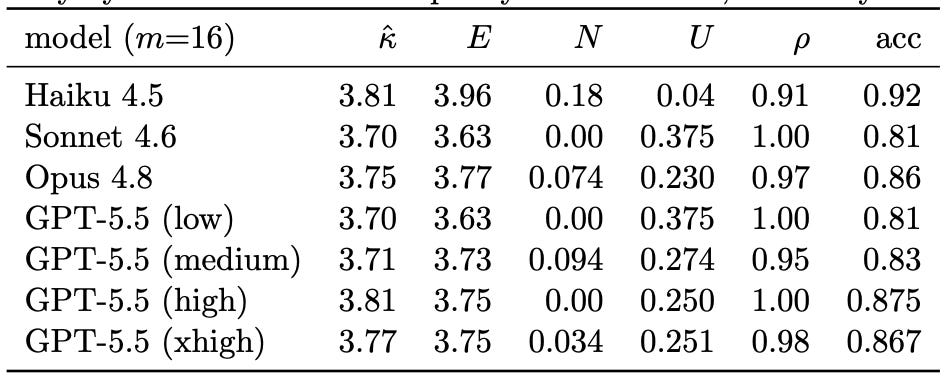
The routing experiment is realistic, which makes it a little muddy. So I ran one more, built to be brutally clean.
Take eight genuinely distinct operations. Now clone each one into near-identical twins — same job, a slightly reworded description — and keep cloning until eight tools have become sixty-four. Sixty-four tools that are really just eight wearing disguises.
A real-world analogy: “let’s give ChatGPT access to Jira, a ticketing system, and GitHub issues from our customers.”
The capacity? Pinned at three bits. Three.
That’s the exact information content of eight choices, and it does not budge no matter how many duplicates you pile on. You can add fifty-six tools and buy yourself precisely zero additional routing. And at sixty-four tools, the strongest models do the only rational thing on offer: they pick eight, ignore the other fifty-six, and never look back. Perfectly repeatable. Perfectly confident.
Using one-eighth of what you handed them, with a full three bits of capability sitting dark.
If that setup sounds contrived, go look at your own stack. This is the “we connected thirty-two MCP servers and now the agent searches across all of them” situation, and it is a trap with a bow on it.
The solution of tool registries with semantic search has dangerous implications as well. Semantic search of what? The tool descriptions? I doubt they are going into the content surfaced by these tools - but that is what is precisely required to ensure you can fit the right content into those three bits.
Near-duplicate tools are reachable variety with no routing capacity attached — calories with no nutrition.
They cost you context, latency, and dollars, and they buy you a model that silently defaults among them. Deduplicate. Namespace. Sharpen descriptions until two tools stop reading like the same tool. Or put retrieval in front, so the model only ever sees the handful that matter for the request in front of it.
Ideally, dynamically surface tool descriptions based on the user’s prompt that help semantically disambiguate when to use what tool.
Thinking harder is not the lever
I’ll be honest: going in, I bet against reasoning.
The reflex across the whole industry is that when a model fumbles you tell it to think harder — and I expected that to do nothing for routing, because the evidence is that the tool decision is largely settled in the model’s hidden state before the visible “thinking” even begins.
Telling a confused model to reason longer about which of two identical tools to pick is like asking someone to stare longer at two identical doors. The staring was never the bottleneck.
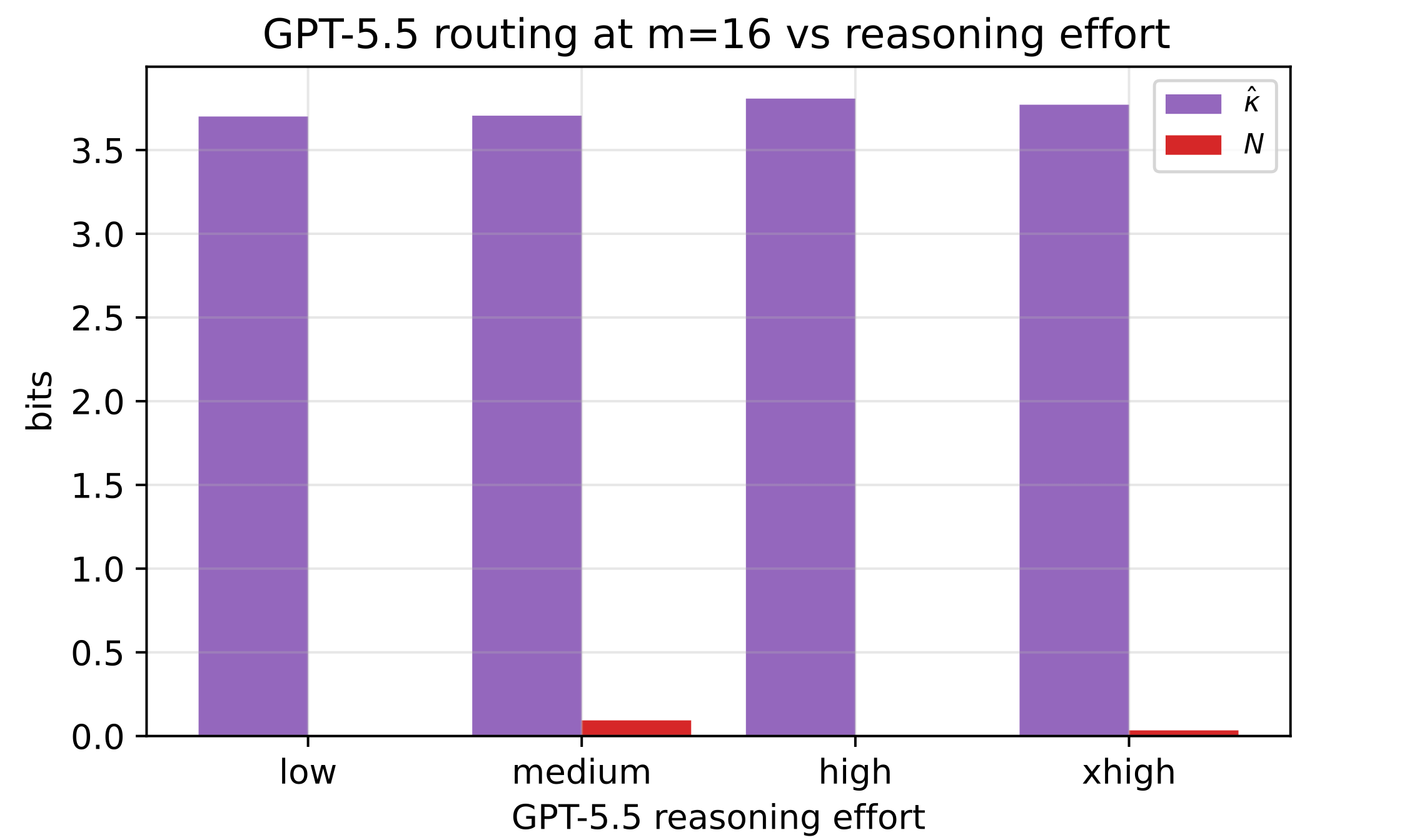
The numbers came back, and I didn’t enjoy being right. I ran GPT-5.5 at four reasoning levels on the sixteen-tool surface, and the relationship was not a straight line up. More reasoning helped — up to a point. Its “high” setting was the best of the four.
But its very highest setting, “xhigh,” burned roughly twenty-four times the output tokens of its lowest — twenty-four times — and came out behind the cheaper “high,” not ahead of it.
The curve peaks and then turns back on itself. Past the peak, the extra thinking didn’t buy capacity; it bought a much larger bill and, eventually, more confident wrong answers.
So: reasoning effort is a wonderful lever for a great many problems. Routing capacity is not one of them, and it is the most expensive knob in the house. Spend that budget on disambiguating your tools instead.
Stacking agents doesn’t print capacity
Then I did what every multi-agent architecture diagram does: I stacked them. A manager agent that reads the request and picks a category, handing off to a specialist agent that picks the actual tool. Surely that buys more capacity — divide and conquer.
The theory is blunt about this. A hierarchy’s capacity is a min-cut: the whole stack can be no wider than its narrowest handoff.
My manager only routed to three categories, so the manager-to-specialist handoff is worth at most log₂3 — about 1.58 bits — and the math says the entire system is capped there. It promptly sailed past it to 3.05 bits, routing all nine intents nearly perfectly.
That is not the theorem breaking. It is the theorem doing its second job — telling you exactly how you cheated. The specialist wasn’t working from the manager’s handoff alone; it was also reading the original request over the manager’s shoulder.
That back-channel — task information leaking past the official handoff — was worth precisely 1.45 bits. Add it to the manager’s 1.58 and you get 3.03. I measured 3.05. The bits reconcile to the second decimal place, which is the moment you stop arguing with a framework and start trusting it.
The lesson for anyone wiring up multi-agent systems: if you want the clean guarantee — capacity capped at the narrowest interface, predictable and analyzable — the specialist must see only what the manager hands it, and nothing else.
The instant it also reads the raw task, you’ve reopened a side door. That can be exactly what you want; it’s why the system performed so well. But you no longer have a min-cut you can reason about — you have a leak, and you’d better measure how much is coming through it.
And adding more specialists in parallel helps only if each one actually widens the binding cut. Bolt on children that all crowd through the same narrow handoff and you’ve added cost, not capacity.
The line at the end of the toolbox
So here is the whole thing in one breath, the version you can act on Monday morning.
Your model has a routing capacity — somewhere around fourteen distinguishable tools on a clean surface, fewer if your tools overlap.
Measure it: run a small routing calibration, find where accuracy starts to fall, and that’s your number.
Then design so that what your agent actually produces stays under that ceiling, even if the surface you expose is larger.
Treat overlap, not count, as the thing to cut.
Watch for the silent failure — a perfectly repeatable agent can be one that has quietly stopped using most of its tools, so monitor accuracy and coverage, not just jitter.
Don’t reach for “think harder” as a routing fix; reach for disambiguation and retrieval.
And when you stack agents, find the narrowest handoff, because that — not your smartest sub-agent — is the ceiling.
This is why the only way to successfully use a coding agent is by gating the output with end-to-end testing. As “code” is the tool, you really don’t have control over any of this, and by it’s very nature it is using a highly granular control surface.
I’ll keep my own honesty bucket full while I’m at it. The cleanest test of all this is still ahead: in these experiments I estimated capacity from the very same data that produced the noise, which makes the wall a consistency check rather than a true out-of-sample prediction — the stronger version calibrates κ on one workload and tests the wall on a disjoint one, and that’s the result I most want to nail down next. Retrieval, modeled as a pre-filter that lifts the routing ceiling, should slide the whole wall to the right; I expect it to, and I’d like to watch it happen. And every number here lives inside a single turn — real agents run for many, and capacity in a long, drifting conversation is its own animal.
But the shape is not in doubt. The tradeoff between a reliable agent, an inventive one, and a cheap one was never three separate fires on three separate Tuesdays. It is one fire, and it has a name and a number now: κ. Everything you build above that ceiling gets paid for — in noise, in waste, and if you’re actually using the surface, in the irreproducibility you’ll be chasing at 2 a.m. for the rest of the quarter.
You don’t get to escape the wall. You get to choose where it bites. Keep what you produce within what you can route, treat overlap as the enemy rather than count, and you’ve made that choice with your eyes open — which is the whole difference between the engineer who’s mystified at tool number sixteen and the one who saw it coming.