
Load Shedding: When Your API Needs an Emergency Brake
Sometimes the Best Customer Option is to Drop the Traffic on the Floor - Try Telling That to Your Manager Yelling "Customer Obsession" Like a Drill Sargent

Let me be clear about something. When your service goes down, it doesn't just affect your Service Level Agreement (SLA). It affects every downstream service, every customer transaction, and every engineer who has to explain to their CEO why the revenue dashboard is showing zeros.
Yes, load shedding makes nobody happy. But let me at least give you some ammo so you can better explain it to your leadership.
The Bottom Line Up Front
Load shedding isn't about giving up on requests—it's about tactical retreat to win the war. When your API starts drowning in requests, you have exactly two choices: intelligently reject some traffic to keep serving the rest, or watch everything collapse under the weight of good intentions gone wrong. The latter is how AWS outages cascade from a single service to half the internet.
1. What Is Load Shedding in Modern APIs?
For RESTful APIs, load shedding is your service's ability to say "no" before it becomes unable to say "yes" to anyone. When your API starts experiencing latency spikes or resource exhaustion, load shedding mechanisms kick in to reject excess requests early—before they consume precious CPU, memory, or downstream service capacity.
For WebSocket-based APIs, the challenge is more nuanced. Unlike REST's request-response model, WebSockets maintain persistent connections. Load shedding here refers to the intelligent closing of connections or throttling of message rates per connection when the service approaches its capacity limits. You're not just rejecting individual requests—you're managing the entire connection lifecycle under pressure.

The key difference? REST APIs shed load per request, while WebSocket APIs must shed load per connection and per message within those connections.
2. Why You Need a Load Shedding Strategy
Here's what happens without load shedding: Your service receives more requests than it can handle. Response times increase. Clients start timing out. Those same clients retry their requests. Now you have double the traffic with the same limited capacity. Rinse, repeat, until your service is spending more CPU rejecting requests than processing them.
The most important request that a server will receive is a ping request from a load balancer. If the server doesn't respond to ping requests promptly, the load balancer will temporarily stop sending new requests to that server, causing the server to sit idle. This is the ultimate irony: your overloaded service becomes completely unavailable because it can't even respond to health checks.
The Universal Scalability Law tells us why: As you add more concurrent work to a system, throughput initially increases, then plateaus, and actually decreases due to contention. Without load shedding, you're forcing your system into the performance-decreasing region, where adding more requests makes everything slower.
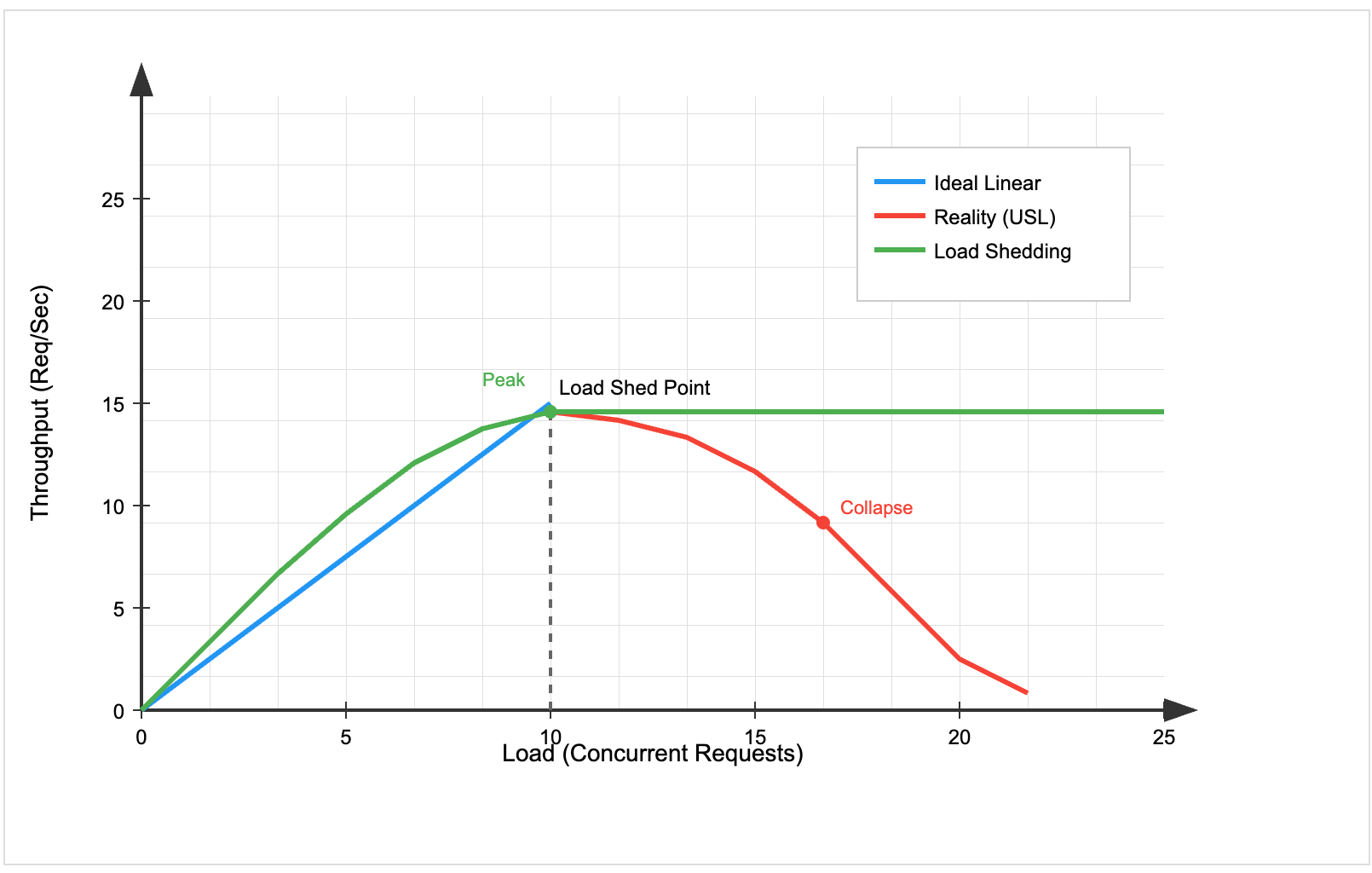
📖 Further Reading: Universal Scalability Law by Neil Gunther
3. The Thundering Herd: When Good Clients Attack
Picture this: Your cache expires at midnight. Suddenly, a thousand clients simultaneously realize they need fresh data. They all hit your API at precisely the same moment. Your database, which was happily serving cached responses, now faces 1,000 concurrent queries for the same data.
A thundering herd incident for an API typically occurs when a large number of clients or services simultaneously send requests to an API after a period of unavailability or delay.
The thundering herd problem manifests in several patterns:
Cache Invalidation Stampedes: When a popular cached item expires, every client tries to regenerate it simultaneously.
Service Recovery Floods: After a brief outage, all clients simultaneously retry their failed requests.
Scheduled Task Convergence: Multiple services running the same cron job hitting your API at identical intervals.
Real-world example: On June 13, 2023, Amazon Web Services (AWS) experienced an incident lasting more than two hours that impacted several services in the
us-east-1region.The root cause involved a capacity management subsystem, but the amplification effect came from clients all retrying failed requests simultaneously as services began recovering.
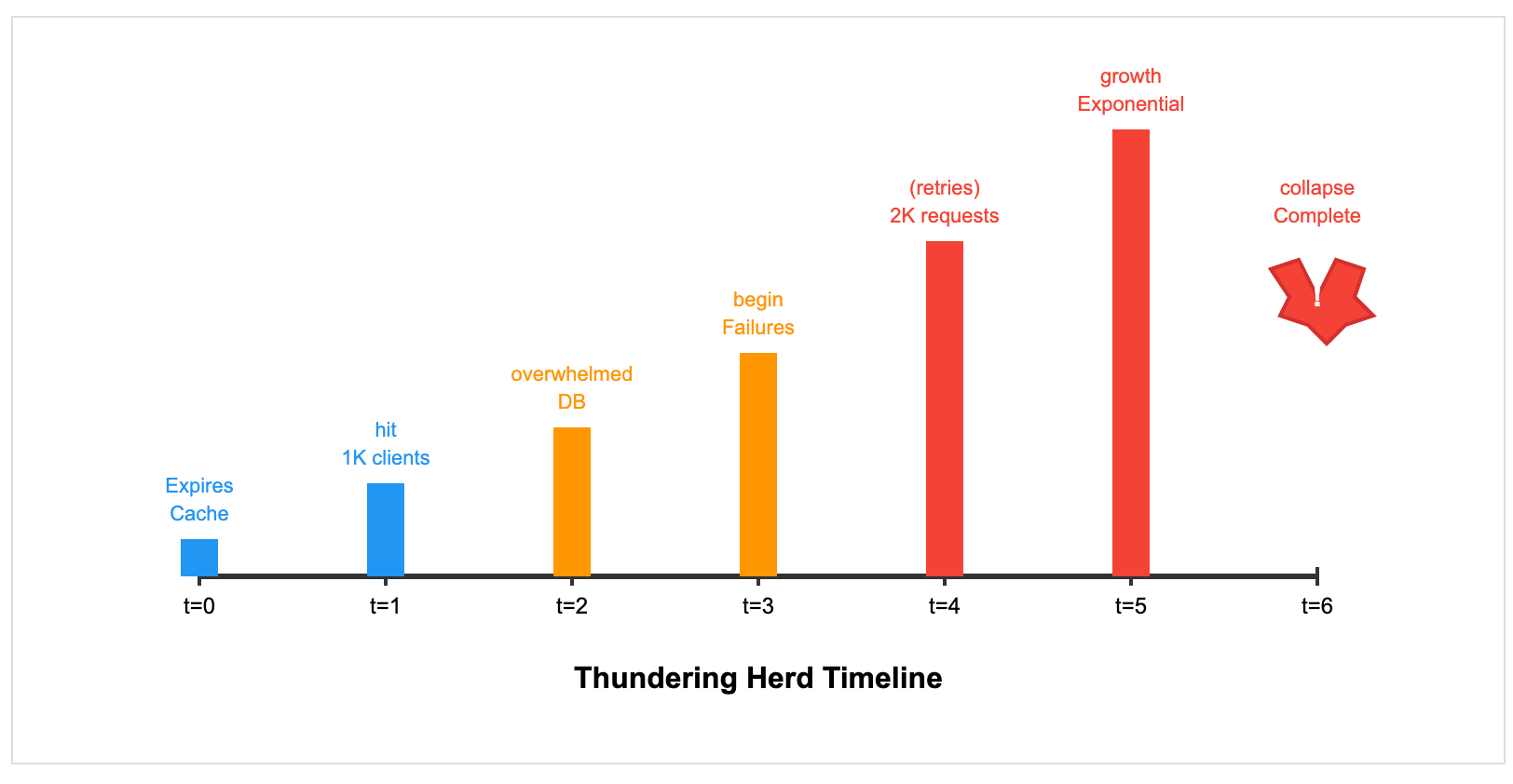
4. How Retry Semantics Create Quadratic Chaos
Let's do the math. Your service typically handles 1,000 requests per second. During a spike, it receives 2,000 requests per second. At a 50% failure rate, 1,000 requests fail and get retried. Now you have 3,000 requests per second (2,000 new + 1,000 retries). This causes more failures, more retries, and soon you're handling 10x your regular traffic.
But here's where it gets exponentially worse: downstream amplification.
One API call to your service might trigger:
3 database queries
2 cache lookups
