
On the Record: AI, Law, and the Indeterminacy of Intelligence
After a month-long hiatus due to a health challenge, I'm back posting again - this time on Substack.

A little context for the reader…
Today, my day started by watching the Karen Read trial on CBS Boston. Yes, I do have an obsession with this drama. Don’t ask. But in my typical random thought process, I was also musing over the drama unfolding as GitHub Copilot tries to solve defects in the .NET Framework, and - well - having trouble doing it. By the way, did I tell you I am also watching Murderbot?
Please do not get me wrong. AI and machine learning work, and they are here to stay, and the random LinkedIn AI-loving and hating posts just aren’t helpful. However, as we begin to adopt agentic AI with MCP interconnects, and the industry as a whole strives to drive independent AI workflows, I worry that we are not considering the law enough. For example, take the .NET Framework. We now have AI bots modifying code in a core runtime used to control machines that purify uranium for nuclear reactors. Are we thinking about the role of AI in the software supply chain?
Lindsay was tired of hearing me talk about it. So, I decided to share it with you instead!
How will AI affect litigation and liability?
There’s a ritual to the courtroom. Oak-paneled, stern-eyed, maybe even a little dusty, but deeply sacred. A place where we presume a simple truth: facts matter. Precision matters. Words matter. In a court of law, the difference between intention and negligence is the difference between liberty and a cell. Every “probably,” “almost,” and “might have” is a pebble in the shoe of justice.
Now imagine asking a machine—an artificial intelligence trained on terabytes of human text, political speeches, grocery lists, congressional records, and bad science fiction—to give you an answer to a question that could determine the fate of a person’s freedom. Imagine asking it, “Did this person commit a crime?” or “Was this financial transaction a breach of contract?”
And imagine that machine says: “Here’s a likely answer, based on patterns I’ve seen.”
Not a certain one. Not an admissible one. A likely one. Now, imagine that the machine supports a workflow where a witness must provide a definitive answer. Do we need to now check if experts are supported by AI? How deep in the information supply chain do we need to probe? My real meditation is about when AI acts independently, lightly prompted by an event, and attempts to take an action. And to be clear, I’m not just worried about the occasional hallucination that is easily discovered and discarded.

The Gradient Whisperer - How AI Actually “Thinks”
I am noticing a horrifying pattern as I talk to CEOs: “Did we check to see if this expense can be eliminated with AI?” Noble gesture, but it needs a follow-up question: “And if it can, are we sure that none of the deliverables can hurt our customers or create a litigation risk?”
For example, was it wise for Microsoft to unleash AI bots on a core foundational library like the .NET Framework? Well, if they had asked the second question, no, it isn’t smart. The smallest buffer overrun in this library can lead to a zero-day vulnerability. A performance impact can slow down safety processes in our electric grid.
“It’s code reviewed, Sid!” you may argue. Well, my dear paisan, code reviews are a last resort, but they are what we would call at Amazon a “good intention.” Core frameworks, such as the .NET Framework, cannot conceivably test for every customer use case, so automated tests are not a reliable backstop either. Shall we all remember the Log4J zero-day vulnerability that cost my team and me dearly?
Down the Gradient Rabbit Hole
Most people imagine AI as a digital oracle: ask a question, get an answer. But what we call “generative AI”—the large language models powering your favorite chatbots and productivity hacks—doesn’t answer questions in a courtroom sense. It completes prompts. It predicts the next most probable word, and then the one after that, and so on, across a spectrum of possibilities.
Under the hood, these models function by sampling from a probability distribution. When you ask, “Is this statement true?” the model is not consulting a fact-checker. It consults a swirling constellation of data points, assigns probabilities, and delivers a response that reflects the most likely pattern based on its training.
The key difference, though, is between asking AI a prompt and using AI as an independent agent. With a prompt, you can clearly inform the user that the response may be incorrect and request verification (passing the liability and responsibility back to the user). With an agent performing a durable action, you now have to rely on a human to enter, inspect the agent, and either approve or reject the work. We know this is error-prone.
It’s a little like asking a roomful of experts, “What’s your best guess?”—except the experts are all ghosts, and you trained them on every book, blog, and bureaucratic memo ever written.
A large language model (LLM) like GPT-4, Claude or Gemini operates by performing a deceptively simple task:
Given a sequence of tokens (words, characters, etc.), predict the next most likely token.
This is achieved using a transformer architecture, where billions (or hundreds of billions) of learned parameters encode the statistical relationships between tokens based on massive training corpora—often scraped from the open web, books, articles, source code, and other sources.
Importantly, this prediction is not deterministic. Most modern models introduce temperature and top-k/top-p sampling during inference to add diversity and creativity to responses:
Temperature controls randomness: a temperature of 0 means deterministic output (always the highest probability token), while higher values increase randomness.
Top-k / Top-p (nucleus) sampling restricts the candidate tokens to a subset of the distribution, either the top k or those cumulatively accounting for p% of probability mass.
This means that the same input prompt may yield different outputs across runs, particularly at default or “creative” settings.
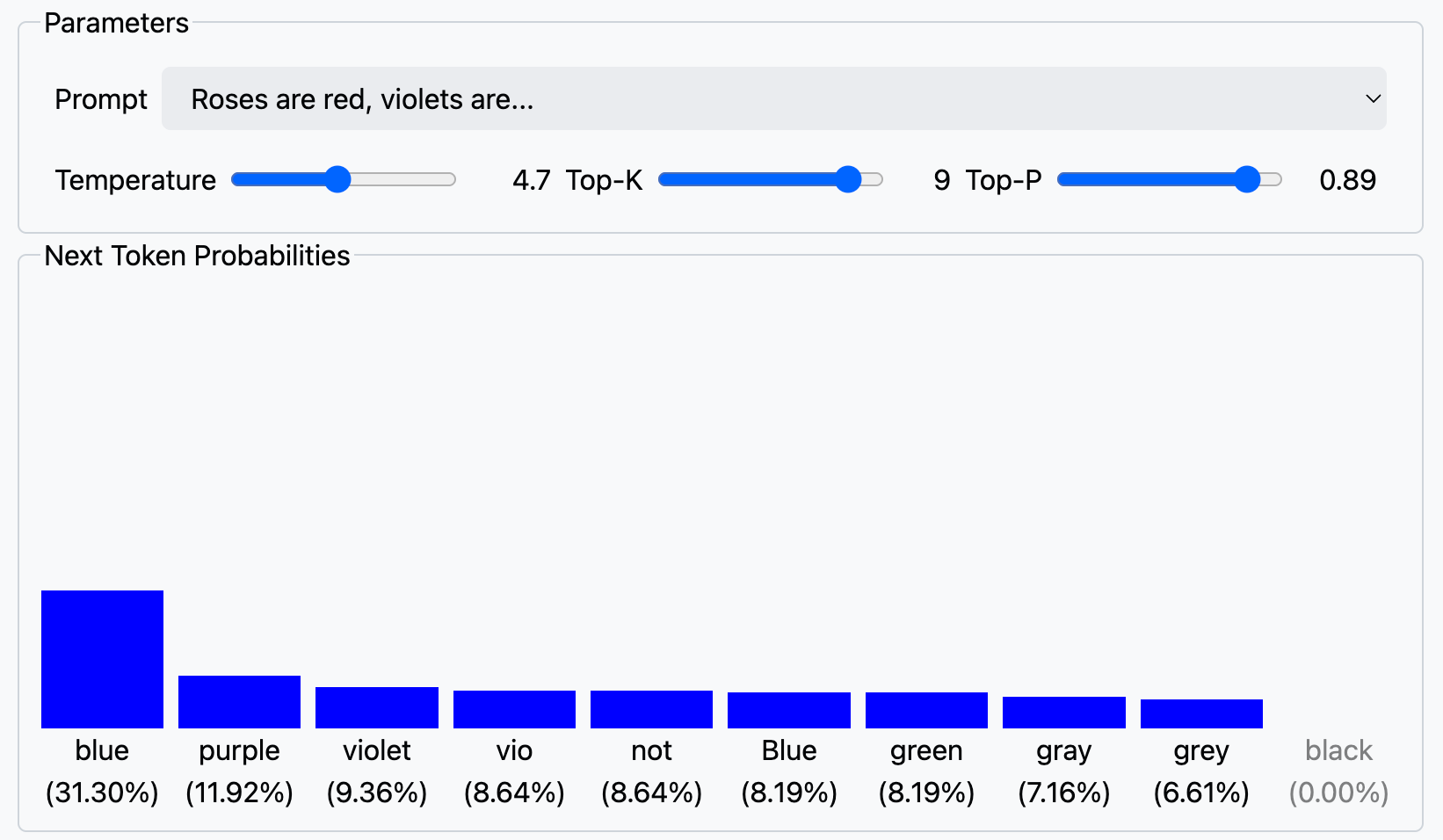
Let me remove any doubt: non-reproducible, non-auditable behavior.
This is not a flaw. This is a feature. It’s what makes generative AI so valuable at everything from writing poetry to diagnosing errors in code. But it is also the precise reason we must be cautious when using it in legally sensitive environments.
I Haven’t Found the Rabbits Yet
1. Language Modeling is Next-Token Prediction
People genuinely don’t believe me when I say Claude is predicting, applying a backspace, predicting again, evaluating what it wrote, and predicting some more. I had an ex-AWS colleague try to convince me that this is the same as humans: “Sid, we edit ourselves too!” No, dude, we have clearly defined beliefs that also provide a measure of ground truth. The model does not. The model depends on many humans providing an ambiguous signal about accuracy through reinforcement learning.
To put a point on it: LLMs are autoregressive models trained to estimate the conditional probability:
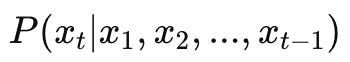
Where x(sub t) is the next token in a sequence. Training involves minimizing the cross-entropy loss between predicted and actual tokens across massive corpora.
This is not fact-checking. This is distribution estimation. The model doesn’t "know" what’s true; it knows what’s likely.
2. And I Have to Mention the Transformers (Cause Autobots Rule!)
The transformer (Vaswani et al., 2017) introduced multi-head self-attention mechanisms, allowing models to capture dependencies across long contexts. LLMs typically consist of:
Input Embedding Layer
Positional Encoding
Multiple Transformer Blocks (with attention + feedforward layers)
Final Linear + Softmax Layer for token distribution
Each token’s representation is shaped by non-linear transformations over many layers and billions of parameters.

3. Multiple Sampling Strategies
During inference, models sample from the predicted distribution using techniques like:
Greedy Decoding: always pick argmax (deterministic)
Temperature Sampling: softens the distribution T→0 increases determinism, T > 1 increases randomness.
Top-k: sample from the top k most likely tokens
Top-p (nucleus): sample from the smallest set
Why This Breaks Legal Norms
1. Non-Determinism Undermines Reproducibility
In law, you need to trace how a decision was made. AI-generated outputs often vary run-to-run. Unless you fix the model version, sampling strategy, temperature, and random seed, you cannot reproduce a given result.
2. Opaque Internal State
LLMs encode knowledge in high-dimensional vectors. There is no explicit reasoning chain, no structured logic path. Interpretability tools (e.g., SHAP, LIME, attention maps) provide approximations, but not definitive logic trees. This violates the legal expectation of explicability.
3. No Grounding in Source Truth
Standard LLMs are pre-trained on diverse internet text. Without grounding (e.g., retrieval-augmented generation), models may hallucinate facts or generate misleading summaries. This is not acceptable in legal briefs or deposition digests.
4. No Known Error Bounds
You can’t compute the confidence interval of a GPT-4 answer in the same way you can measure inter-rater reliability or classifier precision. Uncertainty is embedded in the model’s learned priors.
5. Not Auditable or Testifiable
AI cannot be cross-examined. It cannot disclose its methodology beyond statistical regularities. It cannot satisfy the Daubert standard for expert admissibility.
A Couple of Bots Walked Into a Bar: Was Their Temperature 98.6?
Let’s now consider a few scenarios in which bots can easily become involved.
The Legal Research Bot
An AI summarizes the depositions in a high-profile case. The summary overlooks a key nuance—namely, that a witness recanted under cross-examination. Is the omission a bug? A hallucination? A probability drop-off?
The model doesn’t know. It doesn’t understand the legal weight of what it leaves out. It operates under a loss-minimization objective, tuned for average-case performance, rather than focusing on edge cases. Regardless, the plaintiff loses. During appeal, can the plaintiff claim ineffective assistance of counsel, namely an AI bot?
A Real Life Murder Bot
A transformer-based model analyzes intelligence reports to prioritize and locate targets to eliminate. It automatically creates missions that commanders can execute. Before you laugh, the Israeli army admitted to doing this in a recent conflict. And I can guarantee you that the United States military is considering the same bot. When it inevitably makes a mistake across thousands upon thousands of such missions, and the commander has no reason to doubt it, the wrong people die. Did a war crime just occur?
A Little Deeper, the Next Crowdstrike or Log4J Defect
The software supply chain can be a complex and opaque monster with a profound impact. A minor Crowdstrike defect (which I can easily see an AI agent creating) took out hospitals, governments, and utility networks. “But Sid, humans caused those defects. Why would a bot be any different?” I hate to say it, but humans have an excellent mechanism for holding other humans accountable through our legal system. We lack an accountability mechanism for AI bots. Who do you hold responsible? The development manager who implemented the bot due to the denied headcount?
Can We Use Agents in Legal Environments?
Probably and Depends. However, there is a considerable amount of work for an enterprise to do before it can effectively unleash bots. This work will involve humans. A CEO should keep this in mind before calculating the ROI of their next AI bot, even in seemingly trivial settings, such as maintaining legacy frameworks (like the .NET Framework).
Here are some tweaks I would have your AI team apply.
Deterministic Inference Pipelines
Set temperature=0
Fix model version/checkpoint
Store seeds + logs
Prompt + Output Logging
Retain full transcripts
Hash + timestamp outputs
Ensure chain-of-custody metadata
Model Grounding + RAG
Use trusted legal corpora (e.g., LexisNexis, PACER)
Yes - this may mean you have to fully control the fine-tuning process of the model, starting at pre-training.
Document citation provenance
Penalize hallucination in fine-tuning
Human-in-the-Loop Validation
Require domain expert review
No unsupervised downstream use
Treat outputs as drafts, not verdicts
This is a long way from “a small bit of fine tuning and unleash your bot” that we see in the demos. I would not recommend vibe coding an agent that has a legal implication. And consider the implications a couple of layers deep, not just at a surface level.
My Closing Argument
Let me say this as plainly as a man with a Harvard JD and a Nobel Prize in Economics can: language models are not lawyers. They don’t reason. They don’t argue. They don’t understand. They predict.
And while that makes them very good at writing bedtime stories and autocomplete, it makes them very dangerous when we ask them to decide who gets a mortgage, who needs medical care, or who stands on the wrong side of the law.
In a courtroom, or a hospital, or a bank, or a power grid, you don’t need poetic probability. You need proof. You need audit trails. You need systems that can be questioned, interrogated, and held accountable. In short, you need answers that stand up under oath.
So let’s not pretend we’ve replaced jurisprudence with fluency. Let’s not confuse statistical mimicry with moral judgment. If we’re going to build machines that operate in the halls of power, then by God, they need to meet the standards of the Constitution—not just the benchmarks of a benchmark suite.
Because anything less isn’t just sloppy engineering—it’s a civic failure.
If you’re a CEO asking, “Can this be replaced with AI?” - carefully consider the downstream legal impact in your ROI calculation.
If you’re a CTO implementing the AI replacement, realize you may have to actually train your own model, carefully control parameters like temperature, and have a clear audit and accountability trail.
If you’re selling the bot, perhaps consider giving the customer controls on the knobs that affect the bot. Provide a CloudTrail-style observability mechanism. Leverage AWS mechanisms to ensure a bot’s answer aligns with logic and ground truth requirements.
A Personal Note
I hope you enjoyed this article. I have made it a personal objective to write one of these a week! Let me know if you have any feedback, questions, or comments. And don’t forget to subscribe to my Substack.