
Simulating Society: Monte Carlo Simulations with LLM Agents
This is what happens when I can't sleep on a Friday night. Good morning, America.

Yawn. Is it already Saturday? And I'm finally old enough to experience heartburn from eating day two spaghetti on a Friday night, going to bed after watching multiple hours of “The War” on PBS (side note: Ken Burns does an excellent job)?
Time to fess up on what’s keeping me up. I’ve been dreaming of massively orchestrating large language models (LLMs) to perform Monte Carlo simulations. So, to you, America, let me walk you through my concept.
I’m actually thinking of building this service. However, before I create a prototype, I wanted to ask my network for their thoughts on this service. And also see who wants to help me build it!
Can You Simulate Society With LLMs?
We're not talking about polling. We're not talking about gut instinct, punditry, or Facebook ad A/B tests. We’re talking about creating a synthetic society, at scale, with agents intelligent enough to simulate the hopes, fears, and reactions of real human beings — before you hit send on your message.
This is a Monte Carlo simulation, 2025 edition. And if you think this sounds like West Wing meets Westworld, you're exactly right.
From Quantum Particles to Human Politics
Monte Carlo methods were invented for thermonuclear weapons development. Now we’re pointing that same statistical firepower at something just as volatile: public opinion.
The approach is elegant:
Create synthetic agents based on real-world data, such as voting history, census records, and even Yelp reviews.
Infuse each one with an LLM — tuned or prompted to represent distinct attitudes, regions, and belief systems.
Feed in a message, a product, or a law.
Simulate.
Aggregate.
Learn.
You don’t get a poll result. You get a reaction distribution: what people might think, feel, say, and do.
We live in a world where the cost of failure is high. A policy misfire. A tone-deaf ad. A message that misses its moment. If we’re going to live in that world, let’s at least give ourselves the tools to predict the fallout before it’s on live TV.
Monte Carlo simulations have been around since the Manhattan Project. But now, for the first time, we can simulate not particles or portfolios, but people. Large Language Model (LLM) agents — synthetic citizens, each primed with their own beliefs, histories, biases — can be deployed en masse to test how your message lands across the spectrum of a society.
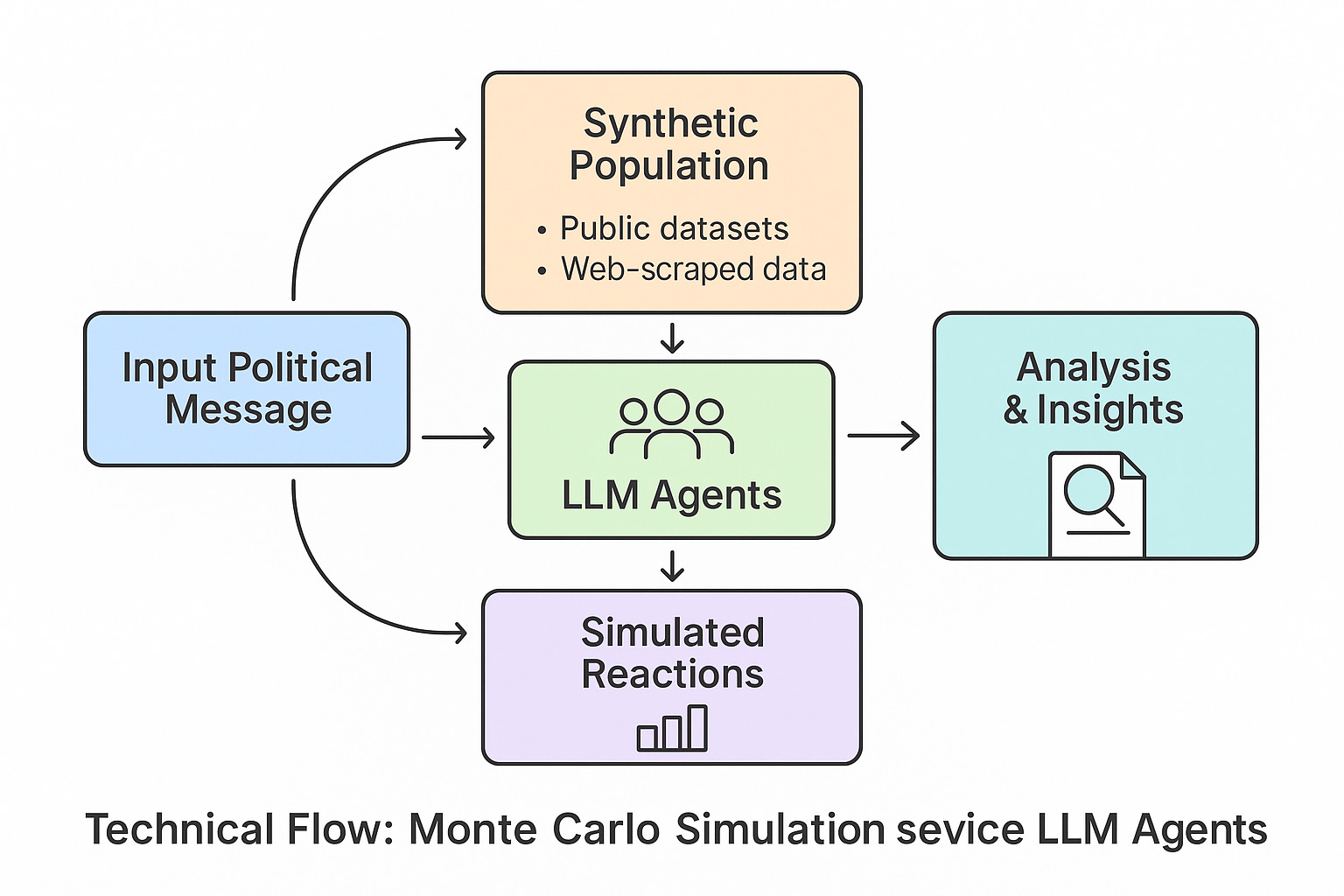
How Does It Work?
Here’s the framework:
You start with a message: a speech, slogan, product, law, or controversy.
You define a synthetic population: using voter files, consumer records, social media data, or scraped web activity. In a marketing use case, this population could come from a tool like Clay, Hubspot, Salesforce, or other CRM data sources.
For each individual, you load or spawn an LLM agent and equip it with:
Public social media data (e.g., Facebook likes, Twitter history, Reddit posts)
Demographic attributes (e.g., age, income, education, voting district)
Personality indicators (MBTI, Big 5, inferred from writing)
Psychographic signals (e.g., beliefs, values, inferred from web history)
Each LLM agent receives the message and responds, simulating interpretation, emotion, behavior, and reasoning.
Simulations are aggregated to produce both quantitative metrics (e.g., support rates) and qualitative analysis (e.g., quoted reactions, contradictions, misinterpretations).
You don’t just get a percentage. You get a transcript of the electorate’s mind.
Now let’s talk use cases.
Applications and the Opportunity
Political Campaigns: Testing Narratives, Not Just Ads
Use Case: Testing a new message on swing-state voters aged 45–65
💥 ROI: Avoid wasting $2–10M on ad buys and messaging that backfires.
Identify high-yield narratives that swing close elections. Generate copy with the highest persuasion delta per dollar.
Implementation Detail:
Start with voter files (public), matched to social media handles via third-party services
Scrape Facebook profiles: post history, likes, political pages followed
For each voter, create a unique LLM agent:
Fine-tune or prompt with scraped content
Add district-specific data, news source preferences, and religious/cultural affiliations
Output: A dataset of synthetic responses — what they liked, what they rejected, how they rationalized it, whether they would share it or distrust it. The response could also be numerical to provide a metric.
“I’m a 57-year-old ex-union steelworker in Scranton, and this smells like another NAFTA.” — Agent 3487
(Hold the phone: this is an actual response from a prototype agent that I built)
Forget a handful of focus groups in Des Moines. With an LLM agent simulation, a candidate can test a new tax policy on:
Evangelicals in suburban Georgia
Union voters in Ohio who voted Obama → Trump → Biden
First-generation Latino voters in the Southwest
Each agent isn’t just a statistic. It’s a simulation: a personality, a worldview, a memory. You’re not polling approval — you’re watching what they think, what they feel, how they might explain it to a friend.
You don’t just test what works. You test what backfires.
Brands & Marketing: Product-Market Fit Before Launch
Use Case: Testing a Gen Z fintech brand launch
💥 ROI: Reduce customer acquisition cost (CAC) by 15–40%.
Pre-test campaigns to isolate copy that converts and suppress ads that alienate.

Implementation Detail:
Pull anonymized segments from CRM or data brokers (e.g. Experian, Axciom)
For each persona: simulate with a prompt tuned on TikTok slang, Reddit sentiment, Robinhood investing patterns
Crawl Twitter bios, Subreddits, and product reviews to generate fine-grained personality prompts
Output: Predict whether the marketing lands as empowering, cringe, or opaque. Run counterfactual tests by altering the copy slightly across agent groups.
“Feels like a boomer wrote this. Use memes, not mission statements.” — Agent 0191
Marketing teams can now simulate:
Reactions to a provocative fashion ad across conservative and progressive personas
A new fintech app pitch tested on Gen Z skeptics, Millennial optimists, and Boomer retirees
Sentiment around a rebrand before the internet drags you
And they can do this on demand. No more six-week agency timelines. You fit the message at GPU speed.
Entertainment and Narrative Testing
Use Case: Evaluating a controversial twist ending in a streaming series
💥 ROI: Avoid reputational damage, refund spikes, and critical backlash.
Improve Net Promoter Score (NPS), increase completion rates, and cut content rewrite cycles in half.
Implementation Detail:
Define agent clusters by genre preference, ideology, and online community (e.g., horror buffs on r/NoSleep, progressive film Twitter)
Feed prior plot elements to agents, followed by the twist ending
Observe comprehension, emotional arc, and backlash scenarios
Output: Viewers calling it genius? Lazy writing? Offensive? You find out in hours, not weeks, after the premiere.
“This retcons everything. If I cared about this character, I don’t anymore.” — Agent 7453
Screenwriters, game developers, and transmedia creators can simulate:
Whether a twist ending lands as brilliant or betrayingly dumb
If a diverse audience feels seen or stereotyped
Player decisions in branching narratives, tested on thousands of agent archetypes
The agents become test audiences — infinitely rewindable, deeply variable.
Policy Simulation: Governing with Synthetic Foresight
Use Case: Gauging the reaction to a universal basic income (UBI) rollout
💥 ROI: Increase the likelihood of policy adoption by up to 3x.
Avoid public relations debacles, court challenges, and rollout misfires. Design smarter, more persuasive messaging before reality hits.
Implementation Detail:
Build agents based on census microdata, segmented by race, region, income decile, and ideology
Use web-scraped comments from local Facebook groups, Nextdoor, Reddit threads about welfare or automation
Feed them the proposed UBI policy document and simulate reactions
Output: A scenario matrix that identifies enthusiasm, concerns, misinterpretations, and likely messaging battlegrounds
“So I get the same check as the guy who doesn’t work? Count me out.” — Agent 5529
Governments and think tanks can simulate the rollout of:
A carbon tax across rural vs. urban communities
A vaccine mandate in politically polarized regions
Police reform narratives among different racial and socioeconomic groups
This isn’t just for messaging. It’s for risk mitigation, trust building, and adaptive policy.
Editor’s note: Notably, this service seemingly exploits the implicit bias inherent in the training data underlying an LLM (either during reinforcement or in the input data).
AI Alignment and Safety
Use Case: Red teaming a chatbot before public release
💥 ROI: Prevent multi-million-dollar compliance failures, reputational collapse, or exploitation of leaks.
Build more robust AI systems while meeting the increasing demands of safety regulations.
Implementation Detail:
Generate adversarial LLM agents designed to mislead, manipulate, or probe for harmful outputs
Simulate multi-agent conversations: attacker, victim, bystander
Test resilience across 10,000 simulated adversaries drawn from a variety of ideological and emotional profiles
Output: Failure scenarios, confusion chains, escalation risks — all caught in the simulator, not the real world.
AI labs and product teams can stress-test how synthetic populations respond to:
Model hallucinations or biases
Provocative or sensitive content
Misinformation campaigns
You simulate not just humans, but agents reacting to agents. A multi-agent, adversarial testbed for real-world chaos.
It’s like Chaos Engineering for AI.
What’s the Killer Demo?
A killer prototype demo is how we kick the door down — here’s the one that will stop a room cold:
Scenario: The National Message Test
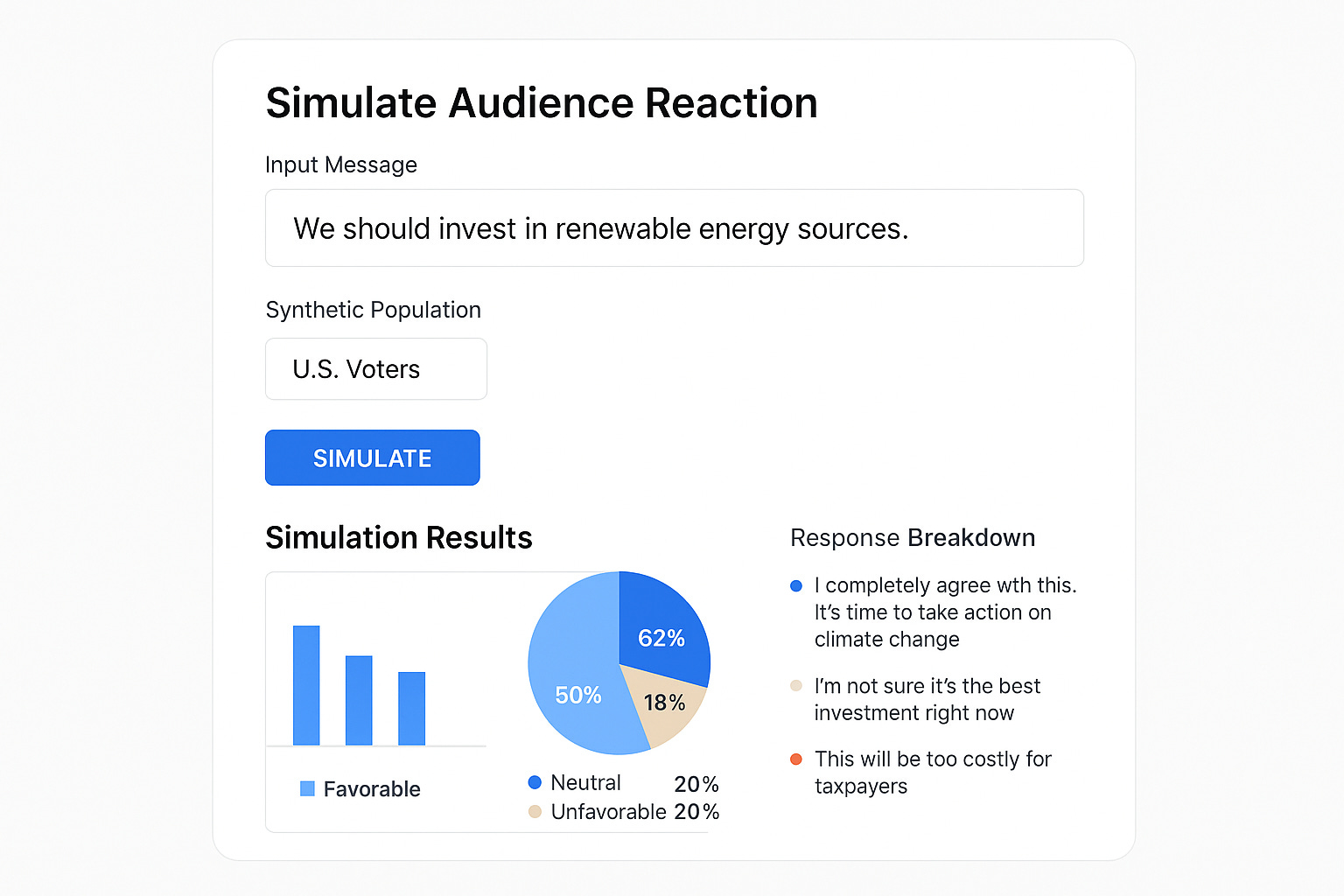
We take a real political message — say, a controversial speech snippet or new tax proposal — and run it through a simulated national population of 10,000 synthetic citizens:
Step 1: Message Upload
A single-click interface enables the transcription of raw text or video.Step 2: Agent Generation
Pull a simulated population from real voter file demographics: age, race, geography, income, education, and digital sentiment profiles.Step 3: Simulation Playback
Watch a stream of individual LLM agent reactions across ideological and emotional spectra. See a map light up in red, green, and yellow for rejection, confusion, and approval.Step 4: Insight Dashboard
"Which 3 lines in the speech drove the biggest swing in trust?" — We show causality, not just correlation.Step 5: Counterfactual Mode
Tweak the message. Change a phrase. Swap the messenger. Watch the new impact live.
Why This Works
It’s visceral. It’s visual. It makes investors say: “I want this before the next election. Or launch. Or crisis.”
And it’s repeatable — brand campaigns, AI safety protocols, policy rollouts. One UI, infinite use cases.
Let’s Move On To The Wife’s (Lindsay’s) Questions. Oh, How Little Faith Ye Have?
How Would You Price a Service Like This?
Market Benchmarks

A Potential Pricing Model

Optional: sentiment heatmaps, live debate mode, scenario replays. Charge for storing agents and the associated memory. Potentially charge for a data visualization/data scientist mode.
I’m Actually Getting Excited About This. Market Size?
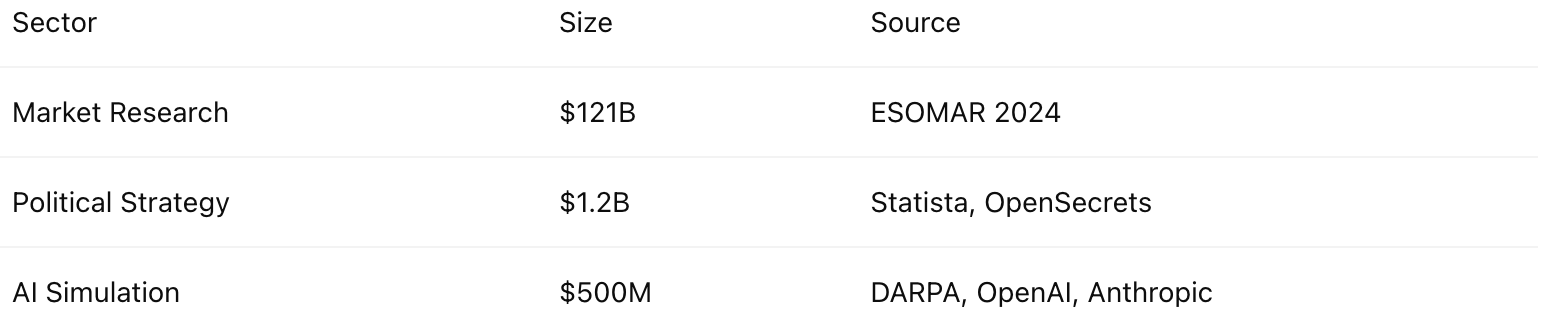
Total Addressable Market
Service Addressable Market (~$3.6B)
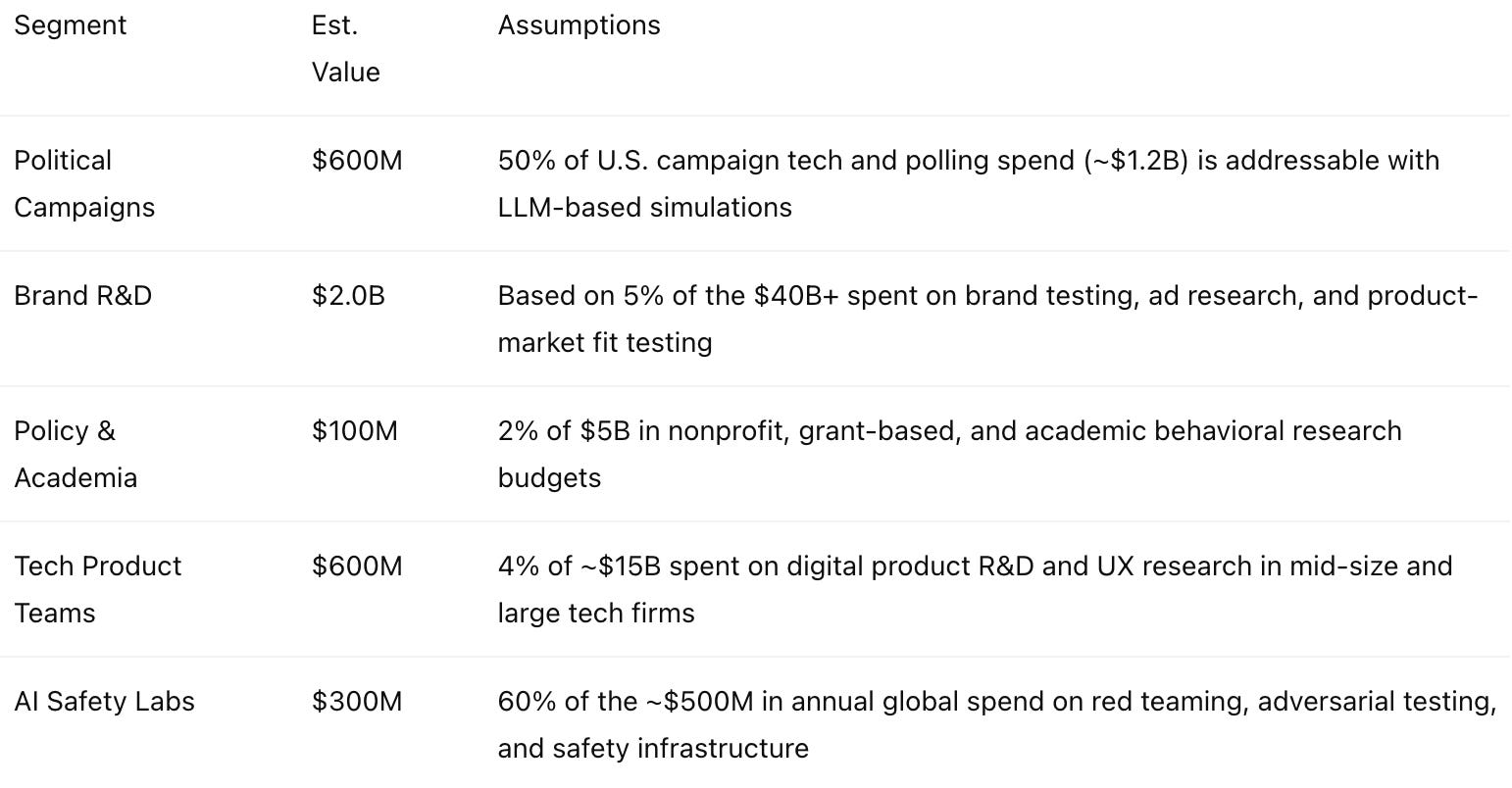
SOM: Serviceable Obtainable Market
First 3 years: $100M–$150M realistic capture
50–100 political teams per cycle
500–1,000 B2B product teams
Safety & regulatory use cases
Just a good old-fashioned SWAG at the moment.
Supporting Sources
Political Strategy ($1.2B):
U.S. federal and state election cycles (OpenSecrets.org, Statista 2024)
Digital campaign spend is ~40% of political budgets; simulation could replace or augment polling, focus groups, and issue testing.
Brand & Consumer R&D ($40B+):
Based on ESOMAR’s 2024 Global Market Research Report: $121B TAM
The top 1,000 consumer brands globally spend ~$10M/year on testing and campaign strategy
We conservatively assume a ~5% wedge for AI-based simulation services emerging in this space
Policy & Academia (~$5B+):
Includes funding from NSF, EU Horizon, Ford Foundation, MacArthur, and Gates Foundation for public response modeling, UBI pilots, and behavioral research
Simulation fits within qualitative/behavioral research spend, which is ~5–10% of these budgets
Tech Product R&D ($15B):
Source: IDC & McKinsey estimates of enterprise R&D on product development in SaaS and consumer tech
Addressable simulation cases include onboarding testing, UX friction detection, and synthetic focus groups
AI Safety ($500M):
Includes published budgets by OpenAI, Anthropic, and federal grants (e.g., U.S. AI EO funding + EU AI Act adaptation grants)
Simulation tools are central to adversarial LLM testing and agent alignment benchmarks
Distribution
The age-old problem for these new concepts. Ideally, we would build distribution directly with the CRM and data source companies (e.g., Clay). But in the absence of these deals, what could we do?
1. Founder-Led Sales in Strategic Verticals
Direct outreach to political consultants, polling firms, brand insight leads, and innovation heads at AI labs.
Use founder credibility and live demos to drive urgency and curiosity.
2. Publish Public Simulations That Drive Earned Media
Run synthetic electorate studies on major events: debates, policy rollouts, ad campaigns.
Publish results as interactive microsites, getting coverage in tech, politics, and business press.
3. Partnerships with Agencies and Think Tanks
Work with polling firms, PR agencies, and nonprofits as channel partners.
Embed simulation into broader offerings for insight-driven clients.
4. Academic and Research Licensing
Provide a discounted, trackable plan for academic labs and journalism schools.
This generates long-term usage and creates future power users.
5. Open Persona Library with Developer Hooks
Allow external devs and marketers to build and share personas, crowd-sourcing new use cases.
Create a flywheel where the most popular personas drive organic usage.
6. Simulation-Driven Landing Page Optimizers
Build plugins that let marketers simulate reactions to site copy, social ads, and signup flows.
Plug directly into standard martech stacks (Webflow, Segment, HubSpot). Integrate with data source tools like Clay.
7. Content + Distribution Loop
Every simulation result becomes a tweet thread, newsletter, video walkthrough, or pitch deck slide.
Show off the output, and people will ask how you got it.
Our go-to-market strategy is simple: prove the platform’s value with irresistible demos, address active pain points, and let the content it produces become our best marketer.
Opportunities to Differentiate
To lead and defend this category, the platform must differentiate on more than just technical novelty. Here's where we can build durable, compounding advantages:
1. Authenticity Through Real-World Data Integration
Instead of relying solely on synthetic personas, our platform can ingest real voter files, CRM data, social media activity, public records, and digital footprints.
This creates LLM agents with grounding in the way real people talk, think, and behave — not generic templates.
2. Full-Stack Simulation Framework
From agent generation and message injection to longitudinal memory and response mapping, we provide an end-to-end loop.
No other platform offers turnkey simulation + analytics + strategy recommendation.
3. Scenario Engine and Causal Testing
Introduce counterfactuals: What if you changed one line? Swapped a spokesperson? Was it released one week later?
Clients can run message evolution timelines and test strategic pivots over time.
4. Regulatory & Ethical Compliance Built-In
Auto-redaction of PII, consent-based simulation for data-enriched personas, and optional bias auditing for agents.
Preempts regulatory scrutiny and positions us as the ethical simulation provider.
5. Network Effects in Persona Libraries
Over time, as clients simulate more audiences and edge cases, the persona libraries become more diverse, realistic, and valuable.
These agent templates can be licensed, shared, or forked across industries.
6. First-Mover Advantage with Thought Leadership
Publish benchmarks, case studies, and synthetic public opinion polls that grab headlines.
Own the category definition in public imagination.
7. API & Platform Extensibility
Let clients bring their own LLMs, run custom fine-tuning, or plug simulation results into internal CRM and analytics tools.
This makes us not just a SaaS tool but a simulation infrastructure layer.
Risks and Pitfalls
While the potential of LLM-powered Monte Carlo simulations is transformative, this category carries serious risks and implementation pitfalls. Addressing them proactively will be critical to long-term defensibility and public trust.
1. Simulation Validity Risk
LLMs are powerful approximators, but they do not "know" or "believe" — they simulate.
Poorly tuned agents may reinforce stereotypes or respond unrealistically if not grounded in real data.
Risk: False confidence in synthetic output leading to real-world strategic errors.
Mitigation: Require population grounding from public datasets, employ adversarial prompt testing, and provide agent confidence scoring and provenance audit logs.
2. Bias Amplification and Misrepresentation
If input data or prompts reflect skewed worldviews, simulations can magnify them.
Without explicit bias auditing, simulated populations may fail to accurately represent vulnerable communities.
Risk: Ethical backlash, reputational damage, and flawed product/policy design.
Mitigation: Introduce fairness classifiers, demographic balance metrics, and periodic third-party audits of synthetic populations.
3. Data Privacy and Consent
Using scraped or inferred data to simulate individuals raises serious privacy and consent concerns.
Even synthetic profiles might raise regulatory flags if derived from personal data.
Risk: Non-compliance with GDPR, CCPA, or future AI governance frameworks.
Mitigation: Apply synthetic persona abstraction (no exact replica), support opt-in/consent workflows for real profiles, and adhere to privacy-by-design standards.
4. Over-Reliance on LLM Internals
LLM behavior is sensitive to prompt structure, temperature, and hallucination.
Without transparent and interpretable tooling, clients may make decisions based on unstable outputs.
Risk: Decision-makers over-trust untraceable model outputs.
Mitigation: Provide explainable AI overlays, standardized prompts, prompt evaluation benchmarks, and include human-in-the-loop gating for high-stakes use cases.
5. Misuse for Manipulation or Disinformation
A tool that helps understand persuasion also enables exploitation.
Simulating "what works" in dark patterns could encourage targeted misinformation.
Risk: Regulatory scrutiny, negative press, and weaponization by bad actors.
Mitigation: Enforce acceptable use policies, build misuse detection models, offer pattern detection dashboards, and partner with watchdog organizations.
6. Economic Scalability and Compute Cost
Simulating thousands of agents across variants requires serious GPU time.
Cost optimization and model compression will be essential to stay accessible.
Risk: Margins collapse under scaling if cloud costs aren't tightly managed.
Mitigation: Invest in inference-time optimization, use LoRA and quantized models, schedule off-peak GPU cycles, and integrate with multi-cloud orchestration tools.
7. Cultural and Contextual Misinterpretation
LLMs trained on broad web data may miss local idioms, slang, or intra-group nuances.
Important for political and international use cases.
Risk: Messages fail or offend in ways the simulation couldn’t predict.
Mitigation: Fine-tune regional sub-models, introduce local validators, use crowd annotation to verify sentiment interpretation, and support multilingual tuning protocols.
Mitigating these risks through transparency, tuning standards, audit trails, opt-in persona creation, and safety-first defaults will be crucial to this category’s integrity and longevity.
Closing Arguments
Here’s the deal.
We’re entering a decade where every message will be scrutinized, every product launch is political, and every policy rollout will hit a fragmented and unpredictable public.
You don’t get the luxury of ignorance anymore. You need insight. You need foresight. You need a feedback loop before the feedback burns you.
That’s what this platform gives us. Not a tool for surveillance. Not a toy for technocrats. A way to rehearse our decisions in synthetic space before we commit them to the real world.
You’ve read the use cases. You’ve seen the market. You know the stakes. But here’s the moral of this story:
The cost of untested communication is collapse. The cost of inaction is irrelevance.
Monte Carlo simulations with LLM agents offer the first real chance to understand—not just what people might think, but how they might change when you engage them. That’s not polling. That’s strategic empathy, at scale.
And if we don’t build it, someone else will. Maybe they’ll use it to persuade. Maybe to deceive. Maybe to sell. But it will be built. And the time to shape its trajectory is now, not later.
We don’t just need this platform because it’s cool. We need it because society is becoming a system too complex to steer without the aid of simulation.
So let’s steer it. Let’s simulate first. Then decide. Let’s lead.
I must admit to myself that at 3 AM, I’m ready to continue building a proof of concept (POC) of this service.
I’m Fired Up! Ready To Go! Who Wants to Help Me Build This?
Sid — love this. I’ve been thinking along similar lines — especially around a GTM simulator to test how both humans and AI agents respond to sales pitches, pricing changes, or complex messaging. But the use cases clearly go far beyond that.
I’ve built a few small prototypes, but nothing at the scale or richness you’re outlining. This feels like core infrastructure for strategic decision-making in an AI-native world.
Examples include:
- Simulating a sales pitch by a human rep across different buyer personas
- Simulating complex sales deals with buyer-side agent behavior (especially for complex deal pricing and margin optimization)
- Testing pricing changes across synthetic market segments
-Evaluating how AI SDR/BDR agents perform against different personas
- Modeling AI infra investments, e.g., how datacenter costs ripple through public markets
Would love to connect — this direction is 🔥.