
Blueprints Over Banter: How a Tiny SVG Outsmarted a Giant Context Window
The autoregression mechanism of transformer-based LLMs simply isn't inherently causal

Context: It has been a tough last couple of weeks for the blind faith of the AI industry. The prophets chortled “Kumare, Kumare” at the top of their lungs as GPT 5 was released (do they ever say a model isn’t a breakthrough?).
I watched as the many Twitter covens and glitterati eagerly debated whether Elon may have gamed his model to pass high school math exams.
Gary Marcus published a Lutheran damnation of the general state of AI. OpenAI claimed it could make a model run for months on the same problem with no human intervention (sorry Sam, I can do that too - and model breakdown and echo chambers are a real problem). Meanwhile, Hacker News was debating the GPT-5 demo fail on Bernoulli.
Generally, except for Gary, all of the prophets have missed the point. The problem isn’t parameters, benchmarks, or how long you run it for. No, the real problem is memory.
Today, I will take you through my personal struggles with LLM memory. I have to admit, Gary may be right over the long term: the most innovative models will not be entirely language-based.
But there are quantum leap practical benefits that can be derived from hacking the models we have right now as well.
You know, the software industry always loves its cycles.
Back when I was a kid, we would always see CPUs zoom ahead, but available RAM always lagged. Like clockwork, Intel (now NVIDIA) would release the latest edition of its CPU, but memory space would not correspondingly increase.
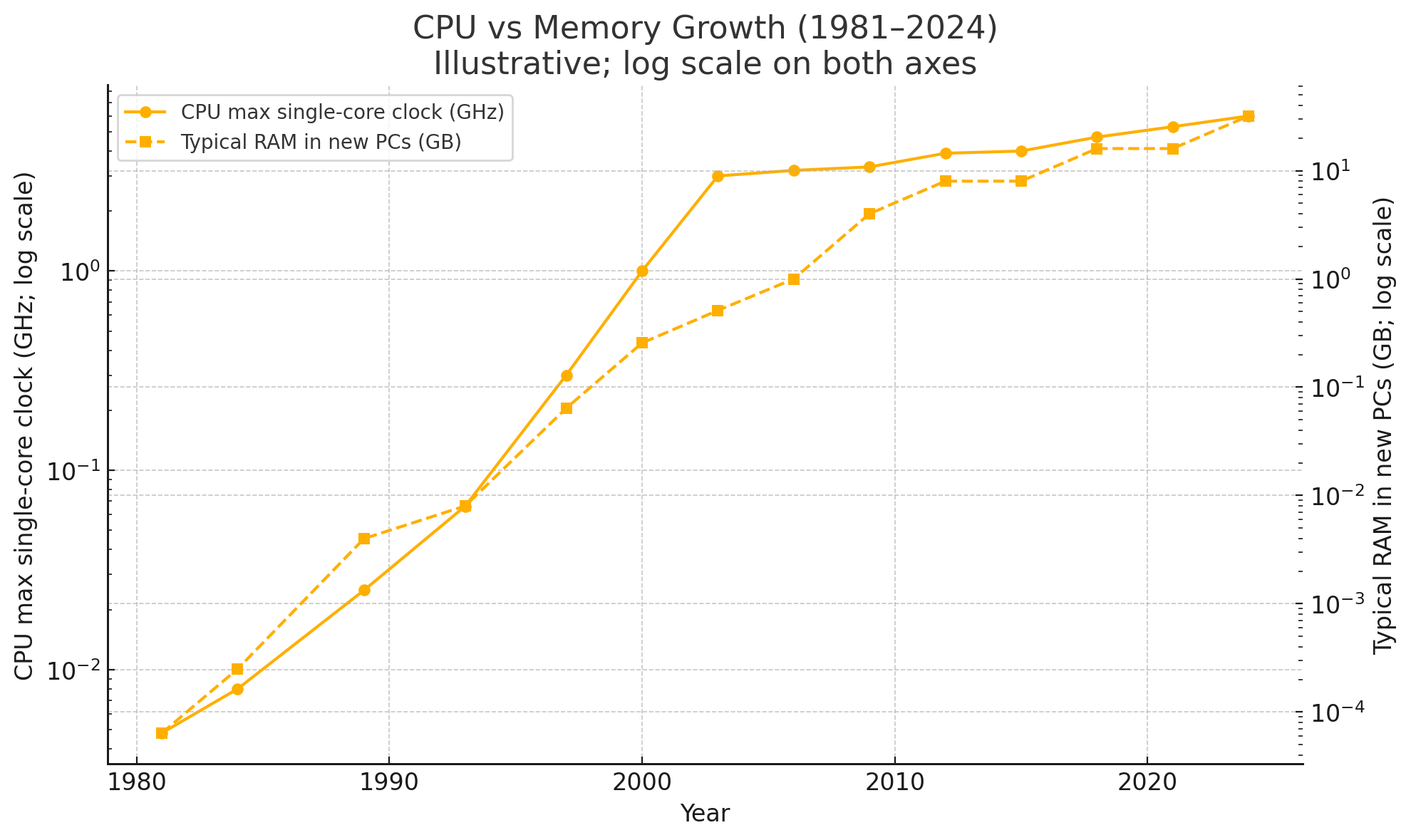
I feel like we are running into the same challenge again, but this time we’re not talking about ephemeral RAM; we’re talking about context.
And before you wring your hands, no amount of broadening the model token context window will ever keep up with the temporal, winding, non-linear nature of human communication and thought.
And what was interesting was that while I watched the prophets fight online, observed my LinkedIn doomscroll debate the valuations of OpenAI and Anthropic, and laughed when Elon asked people to convert their repos into one large text file to submit to Grok 4, I was quietly counting Supastate fatals.
What is a Supastate fatal, you may ask?
Well, let me catch you up. Supastate enables Claude Code to restore an arbitrary context based on a topic. When a developer switches tracks to another part of their project, the last context compaction is relatively useless. So, how do you get Claude Code up to speed? Well, naturally, you semantically search the chat history, and then use Claude Opus to create a summary context to restore context.

But I nervously watched as, roughly half the time, the context wasn’t helping Claude Code. It was finding the right chats and code, but it just wasn’t helping.
Why? I naturally assumed it was a problem with Supastate. As I dug into the problem, I would learn a far more profound truth:
While LLMs are an awesome step in the AI journey, the subprime analogy given to AI economics is valid until we solve the memory and coordination challenges. And that may mean we have to start over.
LLMs: Borg-like CPUs, Dog-like RAM
There’s a particular kind of heartbreak that only modern knowledge workers know: you lovingly explain a problem to your AI, it nods like a golden retriever with a Stanford CS minor, and five minutes later—poof—your context is gone like Wordle on hard mode.
The next sychophantic reply arrives with the confidence of a TED Talk and the memory of a Snapchat thread.
I mean, even Max has a more extended memory. For example, he remembers that the dental chew bone treat he gets every night is his equivalent of puppy heroin, and his mom is a mean, teasing, daily drug dealer at 8 PM. I’m not sure Claude Code could remember what it wrote 15 minutes ago.

Claude Code has a (terrifying?) workaround user experience to solve for this - compaction. As you interact with the model to write code, you can ask it to compact at working breakpoints, or it will automatically compact for you when it runs out of context windows. The way it seductively continues to work across compactions on the same topic lures you into believing that it has retained context.
Yes, some dilution occurs as information gets continuously compacted, but it appears to work well for continuity. Well, that’s good window dressing around the U-shaped curve of importance models place on information at the beginning and the end of the sequence. From Nelson Liu and team’s amazing paper:
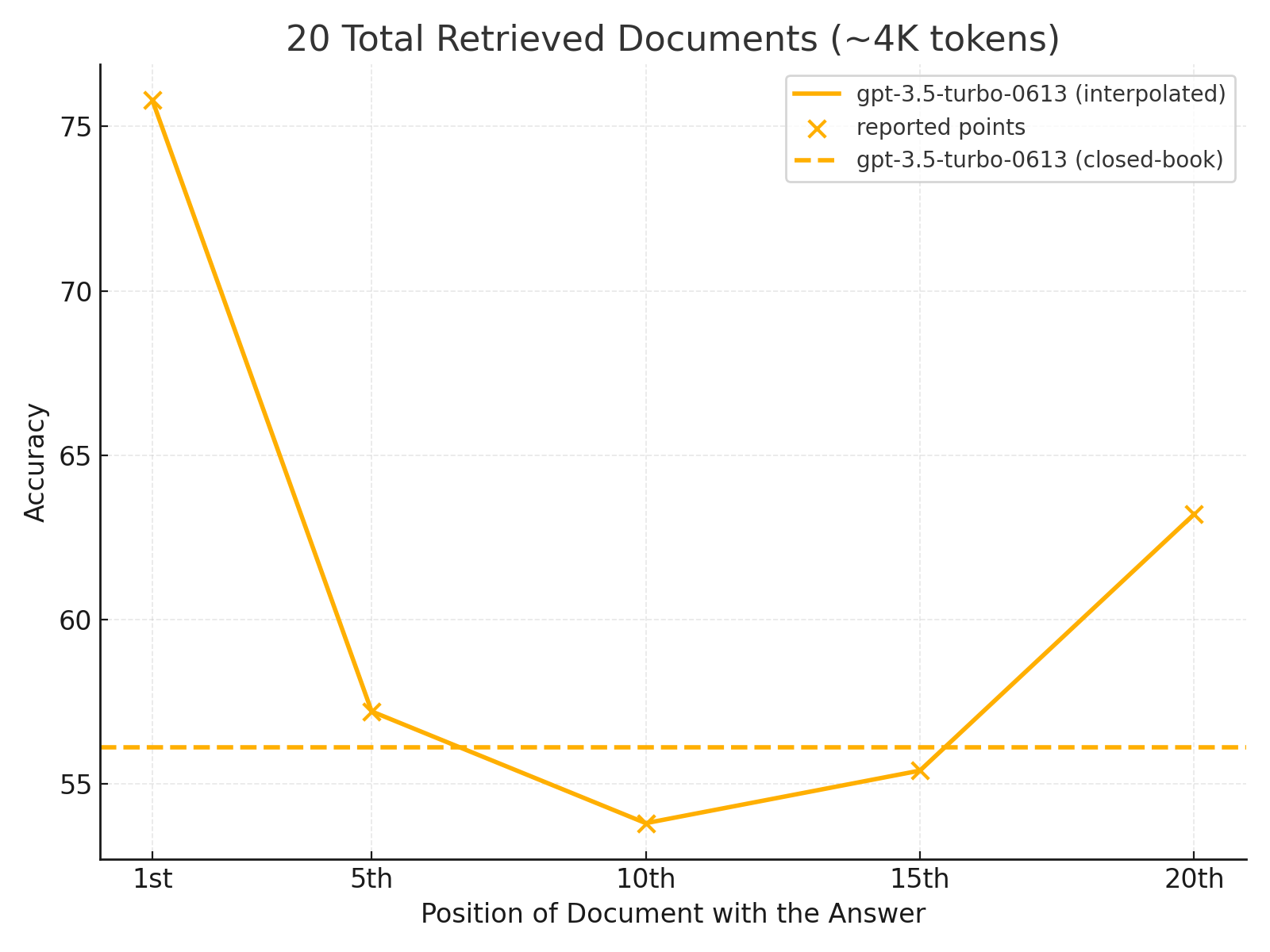
We have all seen it before in simple prompt engineering. The first and last things you write in the prompt are brutally prioritized. Unfortunately, this is not how humans think about problems. With iterative coding, we are delighted because the last iteration tends to be the most important - until you get into a large, multi-step project.
But, back in July 2025, I had fallen hook, line, and sinker for the user experience tuxedo. I built Supastate to provide context restoration from arbitrary topics. After all, something was better than nothing. Then came the plot twist worthy of Black Mirror: today, Claude rolled out an official “reference past chats” feature in its web product. Helpful if you explicitly ask for it; opt‑in; landing first for paid tiers. Great timing, Claude. Bold move.
However, by this week, I could tell from using Supastate an uncomfortable truth: a memory feature ≠ usable memory. Simply recalling historical chat threads wasn’t going to cut it.
The uncomfortable diagnosis: Long Context ≠ Good Context

First, let me give you some interesting metrics:
Only 58% of Supastate’s context restorations were helpful to Claude Code. I added two hooks into my (personal) implementation of Supastate. First, every time I gave Claude Code an entirely new set of tasks, I would ask it to restore context about the task using Supastate.
How? Claude Code would generate semantic search terms for the new task and pass them to Supastate. Supastate would search a vector index of all historical chats and a CRAG-based search of code, combining a semantic and syntactical search strategy. It would return the resulting chunks back to Opus, which would use a prompt almost identical to Claude Code to generate a context summary. This summary would be provided back to the Claude Code instance executing the task. Then I would ask Claude Code to evaluate whether the context helped complete the task. To aggregate the metric, I would (we’re back to Inception) use the same vector index to search for these operations.
In 93% of the cases where the context restorations were not helpful, Claude Code consistently complained about a lack of “architectural understanding.” This is LLM code for reasoning. When I manually audited these failures, I noticed an interesting pattern - dependencies and references. Claude completely missed relationships. Summaries didn’t help. Notes to linked references didn’t help either.
These metrics didn’t get better when Claude Code was given access directly to the knowledge graph. I figured I must be doing it wrong. After all, I didn’t build the model. The folks at Anthropic are brilliant. Well, the model doesn’t do a better job either. When I alternatively gave the model direct access to three tools: (1) the ability to run its own semantic searches (with optional summarization); (2) direct access to the relationships and the graph; and (3) the ability to create stored concepts to help it build an architectural understanding, it performed worse (31% context restoration rate).
For those who believe vectorizing large enterprise knowledge stores and throwing it at LLMs will make AI more intelligent, watch out! This is the number one pattern I have seen a sickening number of CIOs take. Let’s take every document we've ever had and stick it in a Pinecone index; our AI will be smart! Let’s install the GitHub and Salesforce MCP tools and provide raw database access! Or better yet, let’s give our AI root access to Supabase! This won’t work. It’s kind of like yelling at your dog. You can throw a lot of English words at him, but he won’t really know precisely what any of them means, and the relative priority of all the information. And your dog’s goal is to please you, not to devise a strategy that uses tools to achieve that goal.
There is a scary belief occurring in the industry (cough, valley) that all we have to do is vectorize large amounts of enterprise data, wrap it in a vanilla query interface, build models with ever-increasing parameter sizes, and voila - we will have intelligent models.
I’ll tell you that my hands-on experience over the last 60 days does not agree - at all.
Here’s the professor‑with‑a‑laser‑pointer part.
LLMs struggle with where facts sit in long prompts. The now‑canonical Lost in the Middle study shows accuracy peaks when facts are at the very start or end and slumps when they’re buried in the middle. That U‑shaped bias survives even in models designed for giant windows. So “Just give it everything” is not a strategy; it’s a vibe.
Compression and re‑packing help. Methods like LLMLingua or LongLLMLingua compress prompts while preserving salient bits and often improve performance, precisely by fighting that positional bias. Translation: less hay, clearer needles.
Benchmarks in code land agree. Tasks like SWE‑bench and repo‑level completion show that real fixes usually require coordinated changes across multiple files. LLMs need more than line‑by‑line autocomplete; they need a map. Code is too exact—and inconveniently scattered across a Fortnite‑sized map of files. Repo‑level work demands stitching relationships, not just remembering a function signature. Research on repository‑level completion and CodeRAG variants is converging on a simple idea: retrieval must be selective, structured, and relationship‑aware.
So when my experiment returned “not understanding the architecture” 93% of the time, Claude said context wasn’t helpful, and I believed it. The model wasn’t failing to read; it was failing to organize.
So It Isn’t Code. It Isn’t Chat. What Is It?
I did see a hint in the original dataset. When context was helpfully restored, I noticed that about two-thirds of the time, a markdown file was in the source code search results. Typically, the design document that I would ask Claude to generate is part of the initial step of building a feature. I was automatically generating a Haiku summary of this design document, which was embedded into the results used to create the restored context.
Unsurprisingly, the best thing for a large language model to remember is… language. I had solved it. World domination, here we come. Chats are too squishy.
If you squint, the cure is apparent: don’t hand the model a transcript; give it a design. So I happily started building a design document indexing mechanism. I stuffed it full of everything conceivable - GitHub issues, markdown files, related links - a massive knowledge source.
But that didn’t help either.
At this point, I was convinced that large language models would never move beyond the simple tasks they were being used for. They just failed to understand and remember relationships. I also noticed that Opus 4.1 was performing worse than Opus 4. I was starting to believe that Gary Marcus was right and we were heading towards an AI meltdown.
But then the data gave me a glimmer of hope.
The surprisingly effective fix: design docs + diagrams, co‑authored
When I forced a workflow that always generated or refreshed a simple design doc—and I mean forced, as in “system prompt: restore context first, then update the canonical doc, do not create a new one”—the number of back‑and‑forths to get on the same page dropped. I didn’t calculate the number of back and forths precisely, but it was obvious in the same way you know a latte is decaf.
Then I added three steps:
SVG diagrams produced by the model during compaction (boxes, arrows, interactions), then summarized in text and indexed alongside the doc.
Then, recurrently give this design document creating tool access to the same set of code and chat search tools Claude Code has access to, enabling it to search its own information space.
Human‑in‑the‑loop edits on the doc, captured and vectorized for broad semantic search.
Between those, context utility in restoration jumped to 84%. Not because I taught the model to “think,” but because I made the structure think for it.
For example, here was a diagram that was automatically created during a compaction event (encoded in SVG):
Weirdly, this diagram means absolutely nothing to me, but when I restored context to fix a bug with this component, in one step, Claude Code knew precisely how it was organized.
If that sounds quaintly neuro‑symbolic, it is. There’s a thicket of evidence that structured representations (graphs, diagrams, programs) make LLMs more reliable reasoners:
Knowledge graphs + RAG (aka GraphRAG) use nodes/edges as first‑class retrieval units and consistently give better multi‑hop answers than pure text chunks. Microsoft Research has been loud about this, and newer surveys echo it.
Diagrams aren’t just clip art. Systems like DiagrammerGPT plan a diagram first (entities, relations, layout) and then render it, improving faithfulness; recent work also tests whether VLMs actually understand diagrammatic relations. The gist: pictures help when they encode relations, not vibes.
Prompt compaction helps models notice the important parts, not just fit more tokens. That’s the LLMLingua line of work.
It may be tempting to immediately go out and spin up your own Neo4J instance, spending thousands of dollars per month. Don’t. I hate to break it to the Neo4J folks, but until models get better at actually running Cypher queries, the value of the graph is limited at best. And until models start thinking in terms of graphs (they don’t), it just isn’t going to help. Which leads me to…
“But you had a whole knowledge graph already!”
I did. And so do many of us. But here’s the rub: just because your system can run Cypher/SQL or swim in an MCP lake of tools doesn’t mean the model will choose to. Tool use reliability is its own discipline (see ReAct and Toolformer), and models are notorious for under‑calling or mis‑calling tools unless you make the invocation required, early, and specific. (Anthropic’s MCP docs explicitly position MCP as the “USB‑C for AI tools,” but the client still needs to plug the cable in.) Much noise was made of GPT-5s ability to run tools, but again, we still have the competition between using valuable context windows to teach the model how to use the tool versus using the tool.
In the meantime, I will still argue that 90% of the development investment into tools has to go into tool documentation and discovery, simplifying the API surface area down to one or two invocations (GPT actually cheats and forces the search endpoint to match their signature!), and realizing that ironically security will yield better context - a feature of tenant isolation is better context.
That’s why Supastate’s approach—make “restore context” a first‑class tool and make docs/diagrams the substrate—felt sane. You give Claude Code a persistent knowledge graph that captures decisions, relationships, and the thread of memory. Then you tell it, in writing, to use those tools first. (That is literally what Supastate’s setup recommends.)
The Playbook
Here is where I ended up making context restoration actually useful. I’m currently hitting a 92% context restoration success rate with this strategy.
1) Mandate context restoration as Step Zero.
Write it into your system instructions: “Before doing anything, call restore_context and update the canonical design doc.” Don’t be polite; be specific. (MCP makes this easy to standardize across projects.)
