
Supastate: The Amnesia Epidemic: How We Gave Claude a Memory (A Technical Journey)
A Technical Journey of Working Through Context Windows... Built by a Developer for Developers

Context: I have not written in a while. No, I have been 100% heads down building. I apologize in advance to the many I have ignored.
After observing over a thousand downloads and a hundred daily active Camille users, I noticed that I was not alone, and many were frustrated with Claude Code’s shrinking context window and increasing cost.
But I also knew Camille had its limits.
So I started building something called Supastate. Here is the story of my ever-expanding goal to improve agentic coders — without waiting on AGI.
If you're interested in using Supastate, feel free to message me on Substack or LinkedIn. It requires a valid GitHub user to authenticate.
Unlike Camille, Supastate does cost dollars to run, so unless you are directly helping me with it, you will have to sign up for a subscription after a trial period.
Let me tell you something about memory. In 1953, Henry Molaison had his hippocampus removed to cure his epilepsy. The surgery worked—no more seizures—but Henry could never form new memories again.
Every conversation, every face, every moment dissolved into the ether seconds after it happened. Now, why am I telling you about a neurosurgery patient from the Eisenhower administration? Because that's precisely what we've been doing to our AI coding assistants, and we've been calling it a feature.
Walk with me here.
The Fundamental Flaw in Our Collective Brilliance
Remember Friendster? Of course you don't. It had 115 million users at its peak—that's more than the population of the Philippines—and it vanished like morning mist because it couldn't handle the load. MySpace had Tom as everyone's friend (a brilliant piece of social engineering, by the way), but it forgot that people wanted consistency, not just customization. These weren't technical failures; they were memory failures. They couldn't remember what made them successful or learn from what was killing them.
Now we've got Claude—brilliant piece of engineering, truly remarkable—and we've given it the same affliction Henry Molaison had. Every time you close that chat window, poof! Gone. Like it never happened. You know what that means?
It means every morning, you're explaining your authentication system to Claude like it's the first day of school. Again.
But it gets better (worse). It loses context all the time. Some of this is the very nature of iterative software development. When you go to fix a bug you found while trying to build an unrelated feature, beware, you better get it done in one or two shots, otherwise it will dilute the context away from the feature you were building. It is challenging to predict how many tokens the next instruction will consume - and frankly, neither can Claude.
The result? You only make broad decisions on how much inventory is available in the current context window.
That’s just not how iterative software development works.
The Graph That Changed Everything (Or: How Neo4j Became Our Hippocampus)
Context for an AI code generation tool is a combination of memories and code interconnected in a graph. Ironically, the context that Claude attempts to keep is an elementary graph. It is an LLM summarization of your chat, with pointers to the code that was modified or created during the session. But code is a rich graph in its own right that combines syntax with semantics. Memories may involve code that was not directly touched or read. In other words, an elementary graph does not do the situation justice. And then add to that a recursively compacting context, and you now have a completely new challenge.
While a lot of focus in the industry has gone into the LLM and its ability to generate complex, multi-step code, I believe not enough focus in the industry has gone into memory. I suppose the belief is that we’re reaching AGI in the next year, so memory is a waste of time to focus on. But, as we know, memory context windows quadratically increase cost. And human code emitters suddenly make a ton of sense.
At the same time, I was absolutely sick and tired of watching Claude invent four different versions of an authentication pattern (with three different bugs each), forget the original purpose of a project, suffer from a compaction bug, or have no idea of context from dependent projects.
So I had to do something about the problem.

Enter Camille
Here's where it gets interesting. I started with Camille, backed by LanceDB and Kuzu—a lovely little embedded graph database that's very promising—and Camille served its purpose for a short while. Until I realized it was creating 16 GB vector stores, the graph was not very rich, and it just does not scale to have each user having to self-manage their own graph and vector database.
Learning #1: Initially, I provided an open graph MCP facility for Claude to query Kuzu, but Claude's code soon proved to be poorly utilized. I quickly learned why.
LLMs will not take the time to learn your schema of an MCP tool. Their priority is to answer the user’s questions, not teach themselves how to use the tools given to them. It makes sense, given the latency versus user experience tradeoff. Some modes, such as Claude’s “research mode,” will do this - but only if instructed to.
The net result is that an arbitrary query API through MCP will not work well with an LLM. This is bad news for the tens of thousands of MCP adapters that have suddenly appeared across the internet as the immediate answer to many software company board rooms asking the question, “What’s your AI strategy?” As I have stated before, you cannot simply take an existing API, wrap it with MCP, and hope the LLM can leverage it. The worst offenders are the RDBMS MCP adapters.
We're also surprised when LLMs do bad things with open query interfaces.
To make a graph mechanism truly sing, we needed a hosted service with enough horsepower to enable queries that are convenient for an LLM to use.
With over 1,000 downloads of Camille after launch, I knew solving the memory problem was worth it.
Enter Supastate
That's when I got to work on Supastate. Supastate started as a multi-tenant version of Camille, until I realized I could significantly upgrade Camille with the distributed processing power I now had.

Supastate enabled us to build a deep, rich graph, simultaneously execute multiple search strategies (semantic, syntax, and keyword), use LLMs to pre-summarize results to save… LLM… context, and integrate some of the learnings (e.g., Hawking Edison) I had from multi-agent simulations and panels into the coding agent.
So we pivoted to Neo4j, and here's what we discovered: A graph database isn't just a database—it's a memory architecture. Think about how your own memory works. It's not a filing cabinet; it's a web of associations. That song reminds you of that summer, which reminds you of that person, which reminds you of that terrible haircut you had in 1997. That's a graph, not a table.
Neo4j gave us 4096-dimensional vectors—pgvector maxes out at 2000, which is like trying to describe a symphony using only kazoos. We could suddenly model the interconnected nature of code the way the brain models memories: not as isolated facts, but as a living network of relationships.
Here is an example of how token counts and memory are related from one of my projects:
{
"id": "ca947d77-029e-4a3f-bfc3-eb8da28c3014",
"type": "memory",
"content": {
"title": "supastate - 8/3/2025",
"highlights": [
"...~126,487 <mark>token</mark>s (~2,530 <mark>token</mark>s per result)\n\n### Claude <mark>Limit</mark>s:\n- **Opus/Sonnet**: 200,000 <mark>token</mark> context window\n- **Safe maximum**: ~79 code results or ~204 <mark>memory</mark> results\n\n### Why Code..."
]
},
"entity": {
"created_at": "2025-08-04T02:10:07.305Z",
"session_id": "9c2ff82e-3555-41b0-bae1-784c133f3a31",
"project_name": "supastate",
"sonnet_summary": "The discussion focused on analyzing token counts for code and memory search results in the context of Claude's limits, revealing that code searches return about 3,231 tokens per result (64,628 total for 20 results) while memory searches are more efficient at 979 tokens per result (19,587 total for 20 results).",
},
"relationships": {
"memories": [],
"code": [
{
"uri": "code:unknown:9b4f02a1-ae3f-4d1d-a819-0112bbcf914a",
"name": "analyze-mcp-token-usage.ts",
"language": "ts",
"relationshipType": "DISCUSSED_IN"
},
{
"uri": "code:unknown:154d7e8e-4f46-4dd2-9f79-ea8030da8cca",
"name": "analyze-search-token-count.ts",
"language": "ts",
"relationshipType": "DISCUSSED_IN"
},
{
"uri": "code:unknown:a0805a59-9836-4788-8ee9-861a6486071c",
"name": "response-optimizer.ts",
"language": "ts",
"relationshipType": "DISCUSSED_IN"
},
{
"uri": "code:unknown:9261729f-8d42-49ce-bd5a-bd5520ab1e08",
"name": "analyze-mcp-token-usage-simple.ts",
"language": "ts",
"relationshipType": "DISCUSSED_IN"
}
],
}
},This graph brought significant power. We had the opportunity to offer a robust search mechanism that prompts Claude to traverse the graph, learning as it progresses.
Combining that with an AI agent for summarization (to save context in the coding agent) as well as a cage-match partner for improving results, Claude may actually get a new girlfriend/wife in Camille after all.
A Ménage à Trois of Search Strategies
Claude Code has several insidious ways in which it consumes tokens. First, it has a grep-based search mechanism, which is excellent for editing code but not as effective at finding related code on a particular topic. For example, if you are searching for an authentication system, you may need to look for terms like "auth,” “2FA,” or other related terms. Claude Code doesn’t do semantic - probably because they wanted to ensure the tool looking for code doesn’t accidentally edit the wrong code.
But the impact of this lack of imagination in search burns tokens in a second way. It will happily regenerate and recreate entirely new code paths. It will also read a lot of incorrect code before making edits. All of this consumes tokens, but regeneration is the worst because, as we know, output tokens are far more expensive than input.
This then leads to the third token burner - it’s kind of like a barn burner, but for your (wife’s) credit card. All of these new code paths create multiple spots for bugs to appear. And because, especially with context compaction, Claude often doesn’t understand context, it can take five or six attempts to fix the correct code path and not the seven others that it has erroneously created.
So while it is great to have a rich graph to feed to an LLM, search was the second area where it needed help. With Camille, we attempted to achieve this using cosine similarity across vectors, with OpenAI as the embedding provider. OpenAI did a great job at finding relevant topics, but it struggled with understanding syntax. Neither did they do a good job with pattern-matching grep queries. So I needed a three-way search engine.
A Three-Way Date With a Chaperone
Here's something they don't teach you at Stanford: Sometimes the best solution is to use two completely different approaches simultaneously - or three. We moved from a single embedding approach to dual embeddings. We implemented dual embeddings—OpenAI for semantic understanding and Google Gemini for code comprehension. You know what we found? They only agreed 67% of the time.
That's not a bug; that's a breakthrough.
It's like having one detective who reads people and another who reads crime scenes. When searching for "async function that fetches data from API," Gemini beat OpenAI by 21.6% on relevance. Not because OpenAI is inferior—it's brilliant at understanding meaning—but because Gemini understands structure. It's the difference between knowing what a sonnet means and knowing it has fourteen lines of iambic pentameter.
But we were still missing the ability to look for patterns. We needed semantic understanding, PLUS syntax awareness, PLUS pattern generation. Three different lenses looking at the same problem:
Semantic: What does this code mean?
Syntax: How is this code structured?
Pattern: What are all the ways this might be written?
The Haiku Pattern Generator (Yes, I'm Serious)
Here's something they don't tell you in the Claude documentation: Claude searches code like a Unix administrator from 1987. It's grep and awk all the way down. Now, grep's a beautiful tool—elegant, powerful, and has been around since Ken Thompson needed to search text files.
But using grep to search modern codebases is like using a metal detector to find your keys in a junkyard. Sure, it'll beep when it finds metal, but that's not really solving your problem, is it?
Claude would search for validateUser and miss userValidation, validateUserInput, and that clever function you wrote at 3 AM called checkIfThisUserIsLegit. It's literal pattern matching in a world that demands understanding.
So we already had checked the boxes with syntax and semantic search, but we needed something for pattern generation.
We taught Claude Haiku to write regex patterns. I know what you're thinking—"Did he just say haiku and regex in the same sentence?" Yes, I did, and here's why it's genius:
When you search for "user validation functions," Haiku responds with poetry:
validateUser—the obvious seventeen syllablesvalidate.*[Uu]ser—the creative interpretationfunction\\s+validate\\w*[Uu]ser—the comprehensive anthology
It's pattern matching with personality. Haiku understands intent, not just syntax. Ask for "REST endpoints for user management" with TypeScript hints, and it generates patterns specific to Express routes, controller methods, and TypeScript interfaces. It's like having a translator who speaks both Human and Regular Expression fluently.
The result? We catch everything—the function you named sensibly, the one you called at 2 AM after your fourth energy drink, and the one your colleague named using their personal interpretation of Hungarian notation. It's the difference between searching with a flashlight and searching with floodlights, night vision, and a brilliant dog.
We additionally provide pointers to related items on the graph, enabling a search to lead to related items.
You know what this solved? Claude's chronic inability to remember that you already implemented something. Before Supastate, Claude would cheerfully offer to help you create a user validation function, blissfully unaware that you had three of them already, each slightly different, like evolution's failed experiments. Now? Claude finds them all, shows you their relationships, and gently suggests that maybe—just maybe—you might want to consolidate before adding a fourth.
What we end up with is this:
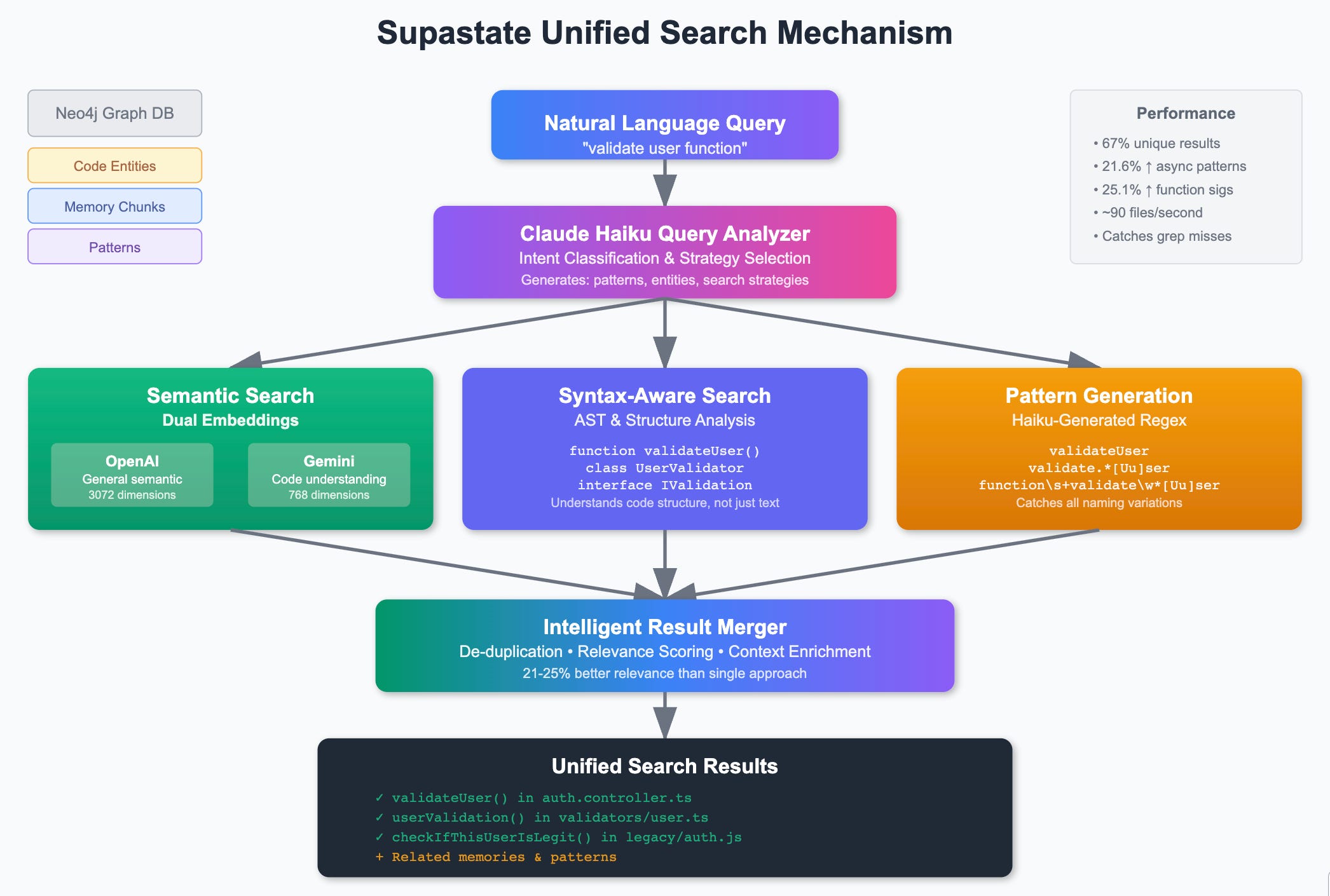
Learning #2: CRAG is not just a “new fad.” It is essential to realize that the vector service does not know whether the LLM is trying for depth versus breadth in the search space, especially in turn-based (e.g., chatbot, non-research) modes. In a research (or deep thinking mode), an LLM may have a sub-agent make this decision for them, but by default, it has no clue. As a result, it is helpful for the search service to support both in its response.
A great example of how this applies beyond code is HL7. With HL7 health data, a model can be devised to provide syntactic understanding to the health records being processed. But other models may yield better semantic understanding (e.g., UTI == urinary tract infection == kidney infection == bladder infection). Using both a depth query (e.g., the HL7 aware parser) with a broad semantic mechanism will yield superb results compared to just using one. The ROI is the LLM tokens consumed as it consumes context (and compacts it) across multiple searches.
The 25,000 Token Wall (Or: How Constraints Create Innovation)
Claude's got a limit: 25,000 tokens per MCP. That's not a suggestion; it's a law of physics in the Claude universe. It's like being asked to perform brain surgery wearing oven mitts—technically possible, but you better be creative about it.
Here's what 25,000 tokens get you:
20-30 enriched code search results (at 3,231 tokens each)
OR 204 memory search results (at 979 tokens each)
OR about half of War and Peace
Not all three. Pick one.
But here's the insidious part—MCP responses don't just hit limits; they blow through context windows with fantastic efficiency. I wanted to give the calling LLM value from relationships, metadata, and many other items - but I could not afford to always return the raw result. My solution? Use another LLM as a subagent.
I wrapped the MCP tools with a token estimator, summarizing the results if the search query returned too much data. This is excellent because, as we discussed, LLMs are terrible about using tools and can easily overwhelm themselves with a firehose of information. And depending on the LLM to get to the correct query is amazingly unreliable. SQL-based MCP tools are bound to fail - end of story.
Learning #3: Use LLMs like Haiku and Sonnet to summarize search results from tools. Have them summarize in Markdown. It will save you tokens and, frankly, get the caller on track faster. You can even cheat by giving the summarization a hint, which then tricks the calling LLM into going down a particular next step.
Search Leads to Infinite Memory and Context
While assisting LLMs in searching and understanding relationships is valuable, we still faced a problem. What occurs when context becomes diluted due to the twists and turns of iterative software development?
I hate to break it to agentic coding developers, but software development is not a linear task. Ironically, agentic coders suck at the super detailed work that you may give an individual entry-level programmer at a FANG company. The attention to detail is just not there, which is what yields the humorous examples, such as the time when Microsoft let GitHub CoPilot loose on the .NET Framework. I often joke with my wife that asking Claude Code to rebuild a feature may be faster than asking it to move a div 10 pixels to the left.
Why, you may ask? Because this is the very nature of language models - they are emitting across a gradient, and rarely understand the multiple layers of algebra (or god-forbid) calculus, involved in how those 10 pixels are rendered. The net result is that builders will often find themselves forking, frequently within a specific context.
Let me paint you a picture of modern software development. Monday: you're building an authentication system. Tuesday: urgent bug in the payment processor. Wednesday: back to auth, but now with OAuth. Thursday: performance optimization. Friday: security audit finds issues in Monday's code.
In a world of auto-compaction, by Friday, Claude remembers Monday about as well as you remember what you had for lunch three weeks ago. Each compaction is a game of telephone where "implement secure JWT validation with refresh token rotation" becomes "did some auth stuff." It's not Claude's fault—it's doing its best to compress War and Peace into a haiku. But haikus, beautiful as they are, make terrible documentation.
Now that we had a relational graph of memories, we could afford to search across this graph and summarize a bite-sized context for Claude to consume to get itself back on track. We reused the search mechanism to generate a new context for Claude to start from!
But then we realized we could provide a set of intelligent panels and tools built on this search mechanism, giving these panels and tools access to the same tools we were giving to Claude. Yes, it was an LLM calling an MCP tool that called an LLM with access to the same MCP tools.
Our initial experiment with Hawking Edison demonstrated that incorporating collaborative agents improved quality. The challenge was integrating these agents into the user experience.
Camille provided us with this gateway.
The Anti-Pattern Museum (Or: Learning from Failure)
You know what's better than making mistakes? Making them once. We built an anti-pattern detection system that's essentially a "Hall of Shame" for bad code. It tracks:
Code that caused problems before
Patterns that led to bugs
Architectural decisions we regretted
That time someone thought MongoDB was the answer to everything

It's like having a friend with perfect memory who gently taps you on the shoulder when you're about to order tequila. "Remember what happened last time?" they whisper. You put down the glass. Crisis averted.
The Monolog System: Rubber Ducks with PhDs
Now, let me tell you about our monolog system, because this is where it gets philosophical. We built on what we learned with Hawking Edison—our multi-agent panel service where LLMs could argue with each other like the Lincoln-Douglas debates, but about code.

The monolog system lets Claude have structured conversations with itself about your code. It's rubber duck debugging, except the duck has tenure at MIT. When you're stuck on a problem, Claude doesn't just listen—it:
Asks clarifying questions based on similar bugs in your codebase
Suggests hypotheses drawn from past debugging sessions
Remembers what you've already tried (and failed)
Connects seemingly unrelated patterns from months ago
It's like having Socrates as your debugging partner, except Socrates remembers every conversation you've ever had and can search through them at the speed of light.
The MCP Accident
Exposing all of these features as simple MCP tools led to an interesting behavior as I built Supastate. My codebase suddenly became a wealth of knowledge that I could use to create everything from the website to documentation, directly from Claude. In fact, I wrote parts of this article by directly using the Supastate tools:
What We Learned Building Supastate
Ecosystem maturity matters more than feature lists. Kuzu had everything we wanted except the ability to use it. That's like having a Swiss Army knife that's welded shut.
Constraints drive innovation. The 25K token limit forced us to build summarization, which made the system better for humans too. It's like how Twitter's 140 characters created an entire new form of literature. Bad literature, mostly, but still.
Memory without context is just data. The graph structure—knowing that this function is called by that controller which was discussed in that debugging session—that's what makes it intelligence.
Team learning beats individual brilliance. When one developer solves a problem in Supastate, every developer's Claude learns. It's like having a hive mind, but one that respects your autonomy and doesn't assimilate you into the collective.
The Philosophy of Persistent Intelligence
Here's what nobody tells you about AI: Intelligence without memory isn't intelligence—it's just very sophisticated pattern matching. It's the difference between a calculator and a mathematician. Both can solve equations, but only one understands why.
Supastate transforms Claude from a brilliant amnesiac into a learning partner. Every conversation adds to its understanding. Every bug fixed prevents future bugs. Every architectural decision is remembered, along with why you made it and whether it worked.
It's not about making AI smarter—Claude's becoming smarter than most of us on our best days. It's about making AI wiser.

Wisdom comes from experience, and experience requires memory.
Looking Forward: The Network Effect of Intelligence
Remember Metcalfe's Law? The value of a network is proportional to the square of its users. But Metcalfe was thinking about telephones. With Supastate, we're talking about the network effect of intelligence. Every developer who uses it makes it smarter for every other developer. It's compound interest for coding knowledge.
We're not just building better tools; we're building tools that become better. Tools that learn. Tools that remember. Tools that prevent you from implementing the same bug that Susan from the frontend team fixed three weeks ago.
Because in the end, the most powerful code isn't the code that's written fastest. It's the code that's written once.
Appendix: The MCP Arsenal (A Technical Deep Dive)
For those of you who've made it this far—and God bless you for your patience—let me walk you through each MCP tool in our arsenal. Think of these as surgical instruments, each designed for a specific purpose, each essential in its own way.
The Search Trinity
supastate_search
This is your universal translator. It searches across code, memories, and GitHub data using natural language. But here's the clever bit: it uses Claude Haiku to analyze your query and automatically selects from five different search strategies. It's like having a research librarian who speaks every language and knows exactly which section of the library to check first.
searchCode
The code-specific search with AI-powered pattern generation. When you provide hints about language, framework, or constructs, Haiku generates multiple regex patterns that complement semantic search. It's finding needles in haystacks, except the needle describes itself differently to different people, and this tool speaks all their languages.
searchMemories
Every conversation, every debugging session, every "aha!" moment—searchable. It's like having perfect recall of every technical discussion you've ever had, except organized and indexed. Searches can be filtered by date, project, or session. Each memory chunk includes related code entities, creating a bi-directional link between what was discussed and what was built.
Context Preservation and Restoration
supastate_restore_context
The amnesia cure. When you start a new Claude session, this tool instantly restores full context about what you were working on. It pulls in relevant code, recent conversations, patterns you've been using, even warnings about what to avoid. It's like walking into a room and having someone hand you a perfectly organized brief of everything that matters.
supastate_check_before_implementing
The time machine. Before you write a single line of code, this tool checks for existing implementations, similar patterns, past attempts (successful and failed), known issues, and best practices. It's prevented more duplicate work than any code review process I've ever seen.
supastate_preserve_critical_context
Some things must never be forgotten—security requirements, API contracts, that one weird bug that only happens on Tuesdays. This tool saves critical context with metadata, expiration dates, and importance levels. It's like having Post-it notes that never fall off and always appear exactly when you need them.
supastate_record_learning
The institutional memory builder. When you solve a tricky bug, discover a pattern, or learn something new, this tool captures it with full context, code examples, and categorization. It's building a searchable knowledge base of your team's collective wisdom, one insight at a time.
Deep Analysis and Reasoning
supastate_analyze_code_with_reasoning
Powered by Opus 4, this is deep code analysis with reasoning that would make a computer science professor weep with joy. It examines bugs, performance, security, and design with the kind of thoroughness usually reserved for doctoral dissertations. But it explains its reasoning in plain English, with examples.
supastate_analyze_pattern_evolution
Give it code examples from different time periods, and it traces the evolution of patterns in your codebase. It's like having an archaeologist for your code, explaining not just what changed but why, and predicting where it's headed next.
supastate_predict_issues
The crystal ball. Based on patterns in your codebase and past bugs, it predicts potential issues: memory leaks, race conditions, error cascades. It's not magic; it's pattern recognition applied to the collective mistakes of your entire development history.
supastate_rubber_duck
The most sophisticated debugging partner you'll ever have. It asks intelligent questions, suggests hypotheses based on similar past issues, and remembers what you've already tried. It's like pair programming with someone who has perfect memory and infinite patience.
Graph Navigation
exploreRelationships
The dependency tracker. It traces relationships up to three levels deep in any direction—what depends on your code, what your code depends on, or both. Essential for impact analysis. Change a function? This tells you what might break.
getRelatedItems
The connection finder. It discovers all items related to any entity through both direct relationships and semantic similarity. It's how you find that utility function you forgot you wrote, or that conversation where someone explained why the architecture works this way.
inspectEntity
The deep dive tool. Get complete details about any code entity, memory chunk, or GitHub item—including content, metadata, relationships, and similar entities. It's like having X-ray vision for your codebase.
Knowledge Management
supastate_list_learnings
Browse the accumulated wisdom of your team. Filter by category (bug fixes, performance improvements, security patches), tags, or date. It's like having a cookbook of solutions, written by your team, for your specific codebase.
supastate_get_learning
Get full details of any recorded learning, including context, code examples, and related entities. Every insight preserved with perfect fidelity.
supastate_list_critical_context
View all preserved architectural decisions, warnings, and requirements. Filter by type, importance, or expiration. It's your project's constitution—the rules that must not be broken.
supastate_get_critical_context
Deep dive into any critical context entry. Understand not just the rule, but why it exists, who created it, and what depends on it.
Advanced Reasoning
supastate_start_monolog
Initiate an Opus 4 reasoning session about complex problems. The AI explores the problem space, gathers context, and reasons through solutions. It's like hiring a consultant who actually knows your codebase inside and out.
supastate_continue_reasoning
Continue a reasoning session with new information. Feed it results, errors, or discoveries, and watch as it integrates them into its analysis. It's iterative problem-solving with perfect memory.
Each of these tools was built to solve a real problem we encountered. Together, they transform Claude from a brilliant but forgetful assistant into a learning partner with perfect recall and growing wisdom. It's not about replacing human intelligence—it's about augmenting it with the one thing we humans aren't great at: perfect memory of everything we've ever done.
Because in the end, that's what Supastate is: a memory palace for your code, a time machine for your decisions, and a safety net for your future mistakes. We built it because we were tired of solving the same problems twice. We're keeping it because it's making us solve better problems once.