
Superintelligence Is Dead. Context Is King.
The $200 Productivity Paradox

Anthropic made a bold declaration when it priced Claude Code at $200 per month for its Max plan.
By setting that price, they essentially told the market what a top-tier AI coding assistant is worth—and it’s not cheap.
From one perspective, the value is absolutely there: a skilled user can treat Claude’s Opus model like a tireless junior engineer, boosting their own productivity by 30-40%. Consider a developer in the US making $200k/year – a 30% productivity gain equates to roughly $60k of work, far above the $2,400 annual Claude Max subscription. In theory, it’s a bargain.
But here’s the rub: not every user is extracting that much value, and Anthropic’s economics are straining under the promise.
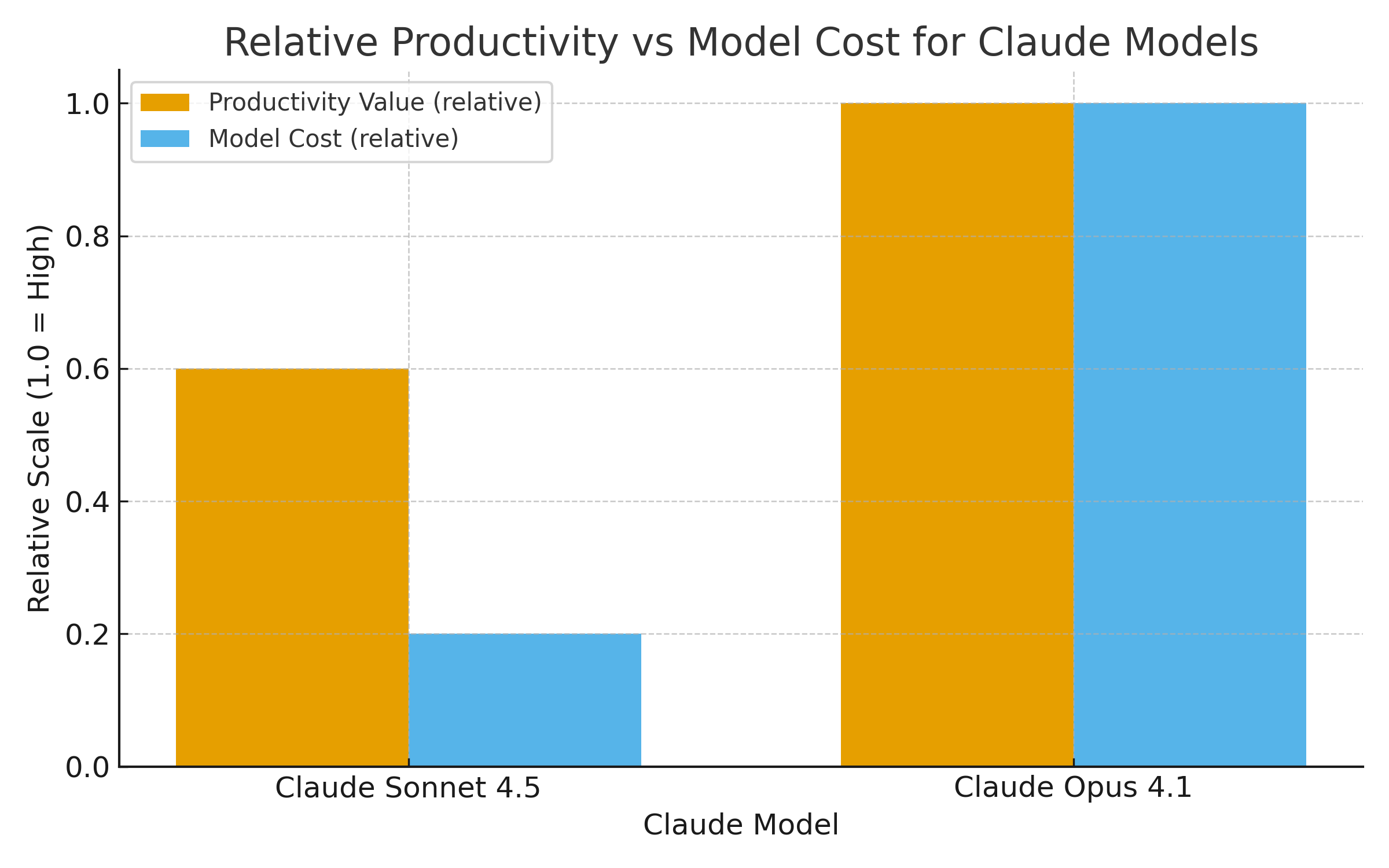
They pegged the price at $200, but to deliver the goods for power users, they must deploy their most advanced (and costly) model, Claude Opus 4.1 – essentially unleashing an AI thoroughbred for the price of a pony ride.
Anthropic’s own marketing acknowledges that the $200 “Max” plan is basically the “use Opus as much as you want” plan. The cheaper tiers either cut you off after a few dozen prompts or shunt you onto the smaller Sonnet model. In practice, $100/month gets you “unlimited Sonnet, limited Opus,” whereas $200 buys you mostly Opus all day.
The high-end model is what heavy-duty users really need—and Anthropic knows it.
The Opus 4 model outclasses Sonnet at complex coding tasks: it understands nuanced instructions better, grasps large codebases more holistically, and sticks the landing on multi-step problems with far less hand-holding. In short, Opus delivers the value that justifies a high price.
Yet Opus is also expensive for Anthropic to run. Every time a user fires it up to refactor a million-line repository or debug a hairy issue, it’s burning significant cloud compute. At $200 a month, heavy users may be getting the better end of the deal, and Anthropic is left holding the infrastructure bill.
This problem exposes a critical flaw in AI economics. This is the actual, true “bubble-risk” of AI—not whether exponential leaps in intelligence will be achieved.
So what’s a business to do when customers love your flagship product but threaten to eat your margins?
Anthropic’s answer appears to be Claude Sonnet 4.5—an updated, presumably more efficient model that they are nudging customers to use for most tasks. In theory, Sonnet 4.5 narrows the gap with Opus 4.1 on benchmarks.
On paper, it’s even better at many things: Anthropic touts Sonnet 4.5 as “the best coding model in the world… the strongest model for building complex agents, and best at using computers,” with state-of-the-art scores on coding benchmarks like SWE-Bench. Essentially, Sonnet 4.5 is supposed to do almost everything Opus can do, at a lower cost. That sounds like a silver bullet for the $200 price dilemma – if it weren’t for one pesky detail: benchmarks aren’t everything.
Sonnet 4.5: Benchmark Star, Creative Dud?
Editor’s Note: One meta-point to take away from this deep dive is that providers derive their cost-optimized models by training (and reinforcing!) them based on how well they perform on benchmarks.
Unfortunately, users’ behavior is rarely captured by these benchmarks.
In practice, Claude Sonnet 4.5 often feels like a step down for those of us used to Opus’s “deep thinking.” Yes, it’s faster and more steerable, and it aces many structured tests.
But somewhere in the quest for efficiency, it seems to have lost a spark of creativity and intuition that Opus had – the very qualities that make an AI feel like a true coding partner.
Advanced users have noticed that Sonnet 4.5 can be frustratingly literal and eager to cut corners. “After months of getting used to Opus’s intuitiveness,” one developer lamented:
Sonnet 4.5 is extremely frustrating… You have to be much more explicit than with Opus. Sonnet does a lot of tasks not in the instructions, and definitely tries to quit early and take shortcuts (maybe Anthropic is training it to save tokens)?
In other words, it’s less willing to go the extra mile in reasoning through a complex problem without hand-holding. Another user concurred, complaining that Sonnet 4.5 couldn’t even correctly generate a simple Angular web form that Opus would have aced. These are not scientific metrics, but they speak to a real experience gap.
Even outside of coding, observers have drawn a contrast between Opus and Sonnet’s “thinking” styles. In one evaluation by a content strategist, Opus 4.1 was the idea machine – creative, bold, occasionally chaotic – whereas Sonnet 4.5 was the meticulous executor – organized, safe, perhaps a bit conventional.
The strategist found Sonnet better for producing polished, structured final content, but noted that “sometimes you need the spark, not the polish,” and that is when she still turns to Opus. Anthropic’s own positioning hints at this trade-off. They recommend using Opus for “maximum creativity and bold ideas” and brainstorming, versus using Sonnet for “strategic analysis” and reliable execution.
Put another way: Opus is the visionary creative director; Sonnet is the disciplined project manager. Both roles are essential – but if you’re trying to get breakthrough coding help or truly innovative solutions, the creative director is the one you want in the room.
So Anthropic finds itself in a bind of its own making. It set a high value bar ($200/month) and delivered a model to meet it (Opus). But that model is costly, and now they’re trying to funnel users toward a cheaper workhorse (Sonnet) that, while competent, may not inspire the same devotion.
The result is a rather convoluted pricing and product scheme – multiple tiers, two different model names (Opus vs Sonnet), limits that reset every 5 hours, and allowances for so many “prompts” here and there. Its complexity stems from economic pressure.
TLDR: They’re trying to square the circle of offering superhuman AI productivity at a human-scale subscription price.
This is the actual, true bubble risk of AI—not whether Zuck can achieve AGI tomorrow, which he won’t.
If you sense some tension in that strategy, you’re not alone. And it hints at a larger truth in today’s AI landscape: we might be running up against a ceiling in raw model capability, and the game is shifting to how intelligently we can use the models—not how big we can make them.
Hitting the Intelligence Wall
Despite all the lofty talk of ever-smarter AI, one suspects that Claude, GPT-4, and their peers have hit an “intelligence wall”—at least for now. No one at Anthropic or OpenAI will say it outright (certainly not when investors are listening), but the plateau is visible.
Each new model version touts marginal improvements or specialized skills, yet none is advancing toward true general intelligence or a profound qualitative breakthrough.
Sonnet 4.5, for all its refinements, is basically on par with Opus 4 in capability – not surpassing it so much as re-balancing strengths and weaknesses. OpenAI’s GPT-4 (released in early 2023) is still arguably the high-water mark for many tasks; a full successor is conspicuously absent in late 2025.
It’s as if the industry hit a sweet spot in IQ and is now pressing against the glass ceiling of diminishing returns.
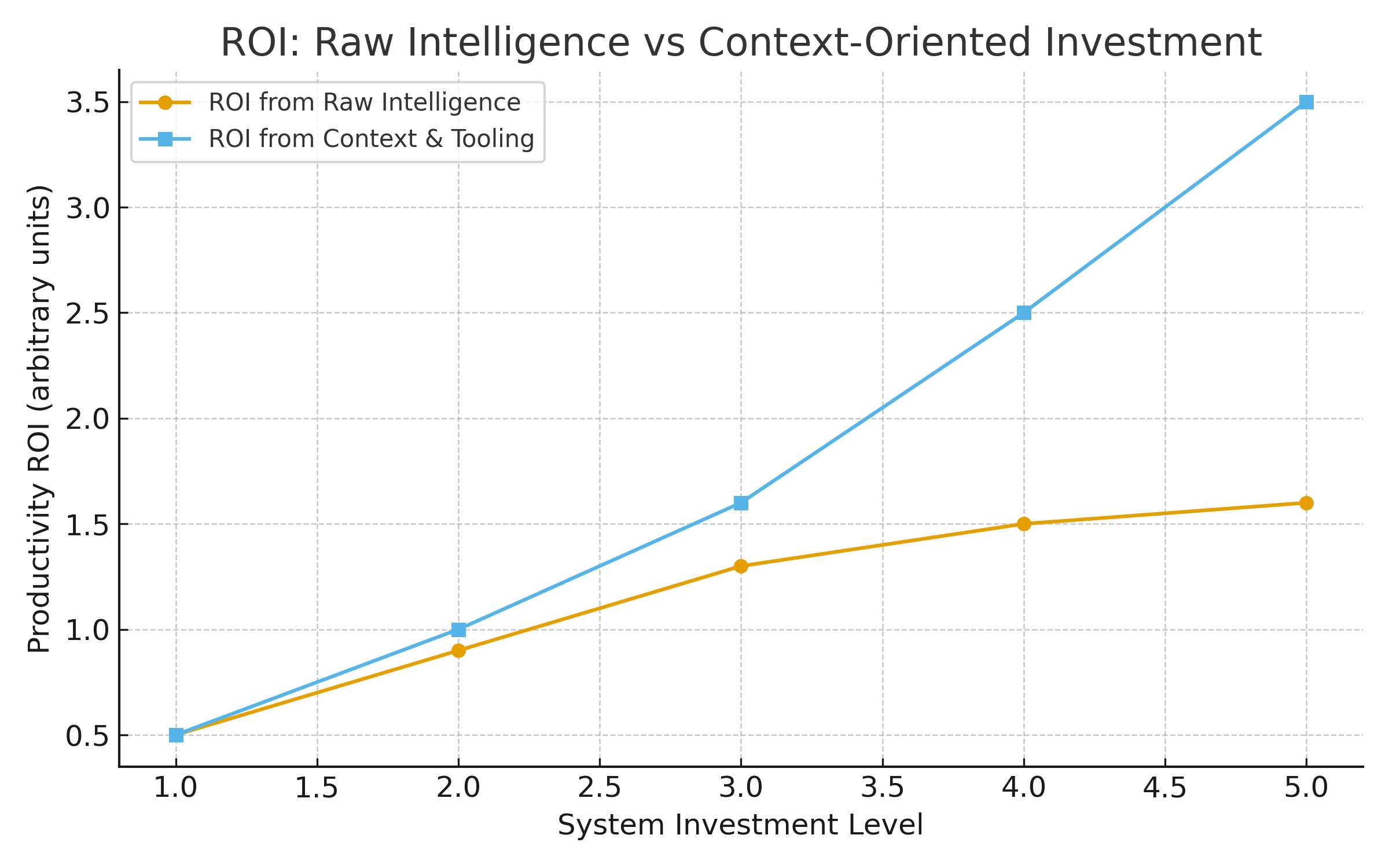
If raw intelligence can’t easily be ramped up, how do AI companies intend to keep improving utility?
The new battlefront is context.
It turns out that how you use the model matters as much as how “smart” the model is. A recent MIT study drove this point home, showing that 95% of organizations are getting essentially zero return on their generative AI investments.
The culprit wasn’t the model quality – today’s best models are skillful – but rather how they were deployed and used.
Most companies simply aren’t integrating AI effectively, leading to a “GenAI divide” in which a few savvy adopters reap benefits while the rest churn out a few trivial chatbot answers with no bottom-line impact. McKinsey echoed this, finding that while 8 in 10 firms have tried GenAI, an equal proportion report no significant effect on their revenue or efficiency. In McKinsey’s blunt analysis, companies are piddling around with AI for tasks like drafting meeting minutes rather than tackling high-value problems.
The message is clear: the bottleneck isn’t that AI isn’t smart enough – it’s that users aren’t giving it the proper context, data, and direction to be useful.
They lack a coherent strategy for feeding the model the correct data at the right times and in the proper format to achieve their overall vision.
This is why “context is king” in the next phase of AI. If a model can’t figure something out, the issue might not be a lack of intelligence – it might be that we haven’t given it the information or guidance it needs.
As Box’s CTO quipped:
“If an AI model isn’t giving you the information you need, it may not be because the model isn’t smart enough; it may be because the model hasn’t been taught how to find the data it needs.”
In other words, it’s the knowledge and context you feed the AI that determines how effective it can be. A robust model failing with the wrong inputs will lose every time to a mediocre model expertly directed with the proper context.
Anthropic’s leadership surely recognizes this, at least on the engineering side. They’ve introduced features like the Claude 4.5 “Haiku” model with a massive 200k-token context and an SDK for “agents” – essentially tools to manage better long conversations, external data, and multi-step tasks. The subtext is that we can’t just make the model’s brain bigger, so let’s give it more memory and better tool handling.
The buzzwords have shifted: last year, it was all about parameter counts and “emergent abilities,” now it’s about context windows, retrieval, memory, and orchestrating multiple agents.
Indeed, one of Anthropic’s bold claims is that Claude Sonnet 4.5 can run continuously for 30+ hours in an “agentic” workflow without losing coherence. Impressive, yes – but note that this is not a pure intelligence improvement; it’s a stability and context management improvement.
And what of the much-hyped “AI agents” that will autonomously perform complex tasks by breaking them into parts? If you peek under the hood, these agents are often just multiple copies of an AI model passing notes to each other.
Don’t let the fancy McKinsey and consulting PowerPoints bedazzle you.
TLDR: Multi-agent orchestration is, in practical terms, multi-context orchestration.
Each “agent” gets its own context window to work on a sub-problem, then shares results with the next. There’s no mysterious emergent group mind – it’s just a clever way to work within the limits of what a single model can pay attention to at once.
As an experienced user, I can tell you: spinning up two AI agents is not like doubling the IQ in the room; it’s more like divide-and-conquer. You give each agent a focused brief. One might analyze a database and output a summary, and another might read that summary to make a decision. This can be powerful, but let’s call it what it is – prompt chaining and context management – not some new species of artificial general intelligence spontaneously arising from agent society.
Side Note: I tried this - with a prototype “AI crowd” with Hawking Edison. It actually generates interesting results—and may be the way to provide the next capability leap. But it does not solve the linked economic problem: how to generate superintelligence affordably.
In short, the frontier of AI usefulness is less about pushing the top-end IQ from 140 to 145 and more about how we marshal the solid 140 IQ we already have to solve real problems. Context – the correct information at the right time, organized cleverly – is now the determining factor of success.
Or, to put it plainly: superintelligence is dead; context is king.
Tools and Memory: The Real Force-Multipliers
If context is king, then tools and memory are the royal court helping the king get things done.
Anthropic understood this when they launched Claude Code. The model alone is powerful, but what made Claude Code initially compelling was the suite of tools around it that allowed it actually to engage with a developer’s world: reading and modifying files, running code, remembering past interactions, etc. Anthropic pioneered the Model Context Protocol (MCP) for connecting AI assistants to external tools and data, which OpenAI bastardized into its own proprietary flavor.
Claude Code integrates with your terminal or IDE, letting it handle million-line codebases and even run code or use a CLI. When you see Claude Code autonomously running npm install or searching your repository, that’s MCP in action – the AI reaching out beyond its native context window.
However, initial success led to new expectations. Once you give developers a taste of an AI that can actually read their whole codebase and remember yesterday’s conversation, they’re going to want more.
And this is where, frankly, Claude Code hit a bit of a wall. For all of Sonnet 4.5’s improvements, many of us noticed that the tooling stagnated. It’s as if the model got smarter, but the “AI assistant” around the model didn’t gain much in the way of common sense.
Claude still had a kind of amnesia between sessions and even within long sessions (despite a bigger context). It would cheerfully suggest solutions that our project already implemented, or rewrite functions from scratch that only needed a minor tweak, because it simply didn’t recall or find the existing code. These are not algorithmic failures so much as context failures.
So, what do engineers do when the provided tools aren’t enough? We build our own. I ended up creating a system called Supastate (with an AI agent codenamed Camille) to amplify Claude’s memory and contextual awareness in coding tasks. The idea was simple: what if Claude never forgot anything significant about your project?
Supastate hooks into Claude Code via MCP and provides a persistent knowledge graph of your entire codebase, along with all past discussions and decisions. It’s like giving Claude a second brain that permanently stores facts and experiences. With this setup, every time I start a task, the AI can restore full context – it can recall, for example, “oh, we have three functions related to user validation already” or “we tried a similar approach last week and it failed, here’s why.” In fact, I literally force the AI to check: our project instructions now say “NEVER WRITE CODE WITHOUT CHECKING EXISTING SOLUTIONS FIRST!” and mandate using Supastate’s tools before doing anything new.
How does it work under the hood? Supastate Camille indexes the codebase and builds a graph of code entities (classes, functions, etc.) and their relationships. It also maintains an embedding-based semantic index of all code, including the conversation history.
When Claude gets a request, say “Add a user audit log,” Camille intercepts it and orchestrates a three-part search of the knowledge base: semantic search (to find conceptually related code via embeddings), syntax-aware search (to find structurally relevant code like anything that looks like an “audit” function), and even pattern-based search using AI-generated regex patterns (to catch variations of terms and naming). The results from these searches are merged and fed to Claude before it attempts any implementation.
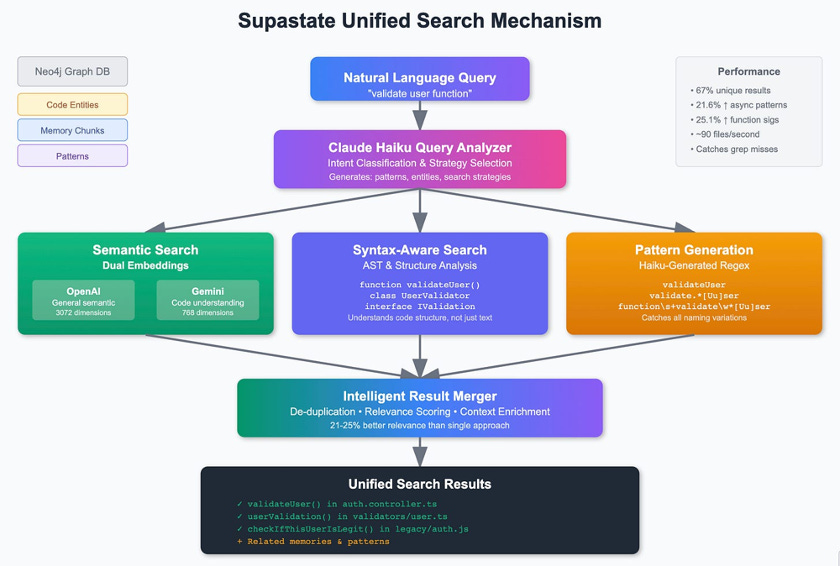
The effect of this is night and day. Without these tools, Claude might blissfully start coding a brand new “UserValidator” class while the project already has UserValidationService and AuthValidator doing similar work.
With Supastate, Claude will instead say, “I found three related functions: validateUser() in auth.controller, userValidation() in validators/User.ts, and checkIfThisUserIsLegit() in the old auth.js – perhaps we should consolidate or extend one of those.”
In fact, that exact scenario played out. Before integrating a persistent memory, Claude would “cheerfully offer to help you create a user validation function, blissfully unaware that you had three of them already… Now, Claude finds them all, shows you their relationships, and gently suggests maybe – just maybe – you might want to consolidate before adding a fourth.
This is the kind of pragmatic improvement that can truly boost productivity. It’s not flashy super-intelligence that magically knows the correct answer:
It’s an AI that is diligently checking its work and leveraging existing knowledge.
It feels less like a clairvoyant oracle and more like an incredibly well-prepared assistant. And to be honest, that’s what most of us need day-to-day. Claude Code became immensely more helpful to me once I added those memory and search augmentations.
The fact that a one-man band with a side project (hi!) could significantly improve the product with some simple tooling should tell you something. There is low-hanging fruit here. Anthropic and others can and should be doing the same, baking this kind of capability in for everyone.
Now, to be clear, I ran dozens of experiments, testing various strategies, model combinations, and latency-reduction approaches to get to this solution. But I do wonder if the conversation in the Anthropic boardroom takes this type of tooling investment for granted.
It is clear that Anthropic, with its billions of dollars, did not invest the same amount of time as a developer sitting in his bedroom did.
For example, even in some of the new tools I have seen Anthropic introduce, they lack the second level of investment into making the tool intelligent by using another model. They have the intelligence of a mouse rather than the eagerness of a puppy. It is almost like Anthropic considers building out these tools beneath them.
Perhaps it is also the economic challenges of introducing a sub-agent…
Empowering the model to use context better beats making the model intrinsically smarter at this point. The returns on better “brains” are diminishing, but the returns on better knowledge and workflow are huge.
Consider also the user experience of these AI assistants. Right now, many AI chatbots are like a blank slate waiting for your questions.
Hot take: That’s intimidating for new users. And f—-ing dumb.
It’s like sitting a person in front of a computer in 1985 and saying “go ahead, type stuff, see what happens” – no guidance.
A more innovative approach would be an AI that proactively gathers context from the user’s environment and suggests how to proceed. Imagine opening Claude and it immediately scans, say, your open documents or recent commits (with permission) and says: “I see you’re working on a payment processing module. I can help by reviewing recent error logs or writing new test cases. Also, you have 100K tokens of context available—here’s my suggestion for how to budget them (e.g., load the critical files, a summary of recent issues, etc.). Shall I proceed?”
This kind of context-aware onboarding could bridge the gap for users who don’t yet speak fluent “AI prompt.” The agent shouldn’t just sit there hoping you know what to ask – it should actively help you leverage the tools and context at its disposal.
All of this underscores the central thesis: the world is now about context management, not intelligence.
We have innovative models; now we need to get much smarter about using them effectively.
That includes better memory, better tool use, clearer strategies for chaining tasks, and more intuitive UIs that guide users. Interestingly, Anthropic’s latest updates nod in this direction—they just released “Agent Skills” and an improved tool interface, which sounds like baby steps toward what we’re describing. But there’s a lot more to do, and it’s going to separate the winners from the also-rans in the AI race.
The Boardroom vs. the Basement
Why hasn’t Anthropic (or OpenAI, or others) fully leaned into this context-and-tools approach? Here we encounter a classic MBA vs. engineering divide. In boardrooms and investor pitches, the narrative that sells is “we’re building a godlike Superintelligence”—a singular AI that will transform everything, justify a $500 billion valuation, etc.
It’s sexy, it’s futuristic, and it loosens the purse strings of venture capital.
You can bet that when these CEOs were raising their mega-rounds, they hyped world-changing AI breakthroughs on the horizon. Meanwhile, down in the engineering trenches, folks are facing the messy reality: current models, while impressive, are plateauing, and the immediate wins will come from clever product design – better context handling, integrations with customer data, reliable memory, fine-tuned domain agents – the not-so-sexy stuff that actually helps customers day to day.
We’ve seen this pattern before. The dot-com era was rife with grand visions that crashed against prosaic execution problems. The AI industry right now is awash in eye-popping valuations and exuberant deals that, to some seasoned observers, “look, smell and talk like a bubble”. OpenAI’s valuation reportedly hit $500 billion (yes, with a “B”) recently – up from $157B just a year ago – and Anthropic’s jumped from $60B to $170B in a matter of months.
These numbers are being thrown around even though both companies are losing money hand over fist.
OpenAI is said to have lost around $5 billion last year on revenue of a few billion.
What’s propping this up? In part, it’s a lemming-like investor frenzy where everyone is afraid to miss out on the Next Big Thing.
And crucially, unlike the dot-com frenzy, because these are private companies, there’s no market mechanism for skepticism. In public markets, if a stock is overhyped, short sellers pile on and send a reality check. In private funding, “the price gets set by the optimists”. Only true believers get a seat at the table, and doubters don’t invest – which means valuations can drift into fantasyland with no one to call bluff.
This is then reinforced by the layoff sprees by the largest companies in the air of a cooling economy, often justified by “potential upcoming AI productivity gains.”
Let’s be clear: these CEOs have not even AI-enabled the most basic tasks in their organizations yet. Still, they are making hopeful, wishful bets on an imaginary productivity improvement to boost earnings by a quarter in a flagging economy.
Thus, the AI centa-unicorn CEOs must keep the dream pumped full of hot air. Admitting “we’ve hit an intelligence wall, so we’re focusing on incremental usability improvements” doesn’t exactly justify a $170B valuation. Instead, we hear about grand AI milestones just over the horizon—artificial general intelligence, multimodal omniscience, you name it.
Meanwhile, the engineers quietly roll out features to make the AI a better team player rather than a genius. It’s a bit of a schizoid existence for these companies: publicly selling moonshots, privately grappling with product-market fit.
Sam Altman isn’t doing TED talks about prompt engineering techniques to improve ROI for insurance companies – he’s talking about godlike AI. Dario Amodei isn’t telling investors that Anthropic’s path to revenue lies in better enterprise data integration—he’s spinning visions of constitutional AI and safe superintelligence. And on it goes.
Herein lies an opportunity. The truth is:
The immediate transformative value of AI will be captured by those who figure out context and integration, not by those who merely have the “smartest” model.
Enterprises don’t necessarily need a significantly more innovative model than what we have today; they need one that plugs into their workflows, their data, and their problems. This is where companies like Oracle, Microsoft, and AWS could shine.
These enterprise stalwarts might not win a model development race against AI startups, but they deeply understand how businesses use software and data. They have decades of hard-earned knowledge about business processes, data management, and customer pain points. If they leverage that – effectively translating their domain expertise into AI-centric solutions – they can guide these AI models to deliver tangible productivity gains that matter.
In fact, we’re already seeing glimmers of this. Microsoft, with its Copilot suite, is wrapping OpenAI’s models in layers of business logic and context (think GitHub Copilot for code, Microsoft 365 Copilot for Office documents).
Oracle is touting how its cloud AI can seamlessly work with Oracle database data through the AI Data Platform, which we launched last week. They are quietly federating and preparing immense, rich data sources into a consistent data stream for AI agents, reserving context for solving business problems rather than figuring out how to connect to disparate data sources.
These companies get that it’s not the AI's IQ; it’s the usability and integration that determine success. They are the ones who can, for instance, connect an AI agent to a company’s entire customer support knowledge base and backend systems securely – something Anthropic alone can’t do from the outside. And customers will pay for that solution, not just raw model access.
TLDR: AI is a feature. Not a product. It always has been a feature.
And OpenAI and Anthropic will need hundreds of billions more in investment to catch up with Oracle, AWS, Databricks, and Salesforce in this game. Sadly, while model choice still matters, models are commodities.
Meanwhile, Anthropic and OpenAI find themselves in a weird position. They have world-leading models, but to actually make money, they have to become enterprise solution providers—a very different game from pure research.
And their current approach (sell API access or subscriptions and hope users figure out the rest) might not scale to the broad business market that still doesn’t know how to apply AI effectively. There’s a whiff of irony here: the AI startups might end up needing the boring old enterprise players to achieve the very productivity revolution that justifies their valuations. But why should investors pay for the value when the strategy has such a glaring gap?
Investor Exuberance vs. Reality
Let’s talk more about that valuation bubble, because it’s the elephant in the room. The AI investment landscape in 2025 is astonishingly frothy. There's speculation that OpenAI might IPO at a valuation well north of half a trillion dollars – more than the current market cap of JPMorgan Chase or Mastercard, to put that in perspective.
Anthropic is raising capital at valuations in the hundreds of billions as well. And yet, when you peel back the curtain, the financials are… well, not pretty. The companies themselves are incinerating cash. The only ones printing money in the AI gold rush are the pick-and-shovel sellers—NVIDIA (GPUs), maybe cloud providers, and chipmakers.
One news analysis put it starkly: “OpenAI is loosely valued at around $500B, yet may make just $13B in revenue in 2025… Anthropic is valued at $183B after a recent round, but is projecting < $10B revenue this year. They’re also spending far more than they earn. Nobody is making money with AI – except for NVIDIA, which is perhaps why it’s so keen to keep pumping the industry.”
This was written after Anthropic claimed it will hit a $9B run rate by the end of this year—an ambitious figure that many analysts view skeptically.
One particularly concerning trend is the circular nature of the mega-deals being struck. OpenAI’s partnership with NVIDIA, for instance, involves OpenAI committing to buy a staggering $X worth of GPUs, and NVIDIA in turn “investing” a similar amount in OpenAI’s equity.
Likewise, OpenAI’s deal with AMD is structured so that OpenAI will use a vast number of AMD chips and even take an equity stake in AMD. It’s almost comical: AI companies are taking the billions of investors gave them and handing it to chip manufacturers, who then plow it back into the AI companies’ valuations.
Here’s the scary part. A lot of this is being done through special-purpose vehicles (SPVs)—the old tactic Enron used to keep deals off the books.
Sound familiar? It should – it harkens back to the dot-com bubble’s vendor financing schemes, where telecom companies bought equipment on credit and the equipment vendors invested in those telecom startups’ stock. One veteran investor explicitly drew this parallel and warned that these AI deals have an uncomfortable rhyme with the year 2000. When money starts going in circles, it usually means actual economic value isn't being created in proportion –
It’s financial engineering to maintain an illusion of growth.
Without public-market scrutiny, these private valuations float on optimism. And as long as everyone involved believes (or pretends to believe) that the next epochal AI breakthrough is around the corner, the music keeps playing.
But if actual utility doesn’t catch up to the hype, something’s gotta give. One of two things will happen: either companies will rapidly learn to harness today’s AI in transformative ways (justifying the investment), or the expectations will implode in a heap of disillusionment.
In either case, the longstanding leaders—Oracle, Microsoft, or AWS—still come out ahead.
I strongly suspect the near future holds a bit of both – some breakaway successes by those who get it right, and a lot of disillusionment from those who don’t. The “GenAI divide” we discussed will become more evident: a small segment of users will derive enormous value (with context-savvy strategies), and the rest will scratch their heads, wondering why their expensive AI subscription isn’t magically solving everything.
Worse yet, we see the “small segment of users” become the oligarchy of the current software industry, leaving the rest of the sector in a hellscape of financial ruin.
If and when the AI bubble pops, it won’t mean AI is over – far from it. It will just mark a shift from exuberance to normalcy, from grand narratives to practical implementations. The short-sellers of reality will finally have their day (figuratively speaking, since you can’t literally short a private company’s hype, but reality has a way of asserting itself eventually).
That correction will actually be healthy. It will force a focus on sustainable business models – likely those that truly deliver productivity gains to customers. And here we circle back to our central thesis:
The real value in the coming years will belong to those who master context, not necessarily those who master intelligence.
The companies that guide users on how to get started, that automatically optimize use of context windows, that integrate with your existing tools and data – they will create genuine, defensible value. The ones that sell “we’ve got the smartest AI, trust us” will either adapt or fade.
Conclusion: Context Over Hype
The era of chasing ever-bigger, ever-smarter standalone AI models for their own sake is winding down. We’ve been to that mountaintop; we’ve seen what today’s best models can do. And they are amazing – but they’re also flawed and costly, and simply pushing the dial from “brilliant” to “even smarter” yields diminishing returns in real-world use. The next leap forward in value will come from embracing a humbler but ultimately more impactful truth:
It’s not about how intelligent the AI is; it’s about how intelligently we can use the AI within real constraints.
“Superintelligence” as a marketing concept may be on life support (sorry, investors), but that doesn’t mean progress is dead. It represents the locus of innovation shifts.
It shifts to AI-assisted context engineering, where companies focus on feeding the AI the right information in the right format (because an ounce of context is worth a pound of model capability).
It shifts to tool integration and automation, where an AI agent doesn’t just idly chat but actively interfaces with software, databases, and workflows, actually to get things done.
It shifts to user experience and guidance, ensuring that anyone can sit down with an AI system and be immediately productive without needing a PhD in prompt crafting.
And it shifts to memory and learning, so that AI systems accumulate knowledge over time rather than forgetting lessons learned with each new session.
We should welcome this shift. It’s a sign of maturation. Think of the early days of electricity – at first, it was all about generating more power, bigger dynamos, higher voltage! But eventually the breakthroughs came from the less glamorous work of distribution, wiring every home, and inventing appliances that effectively used electricity.
We’re at a similar inflection point with AI. The “power” is there; now we have to build the infrastructure and appliances around it.
Context is the wiring, the plumbing, the interface layer that will bring AI’s value into every nook and cranny of our world.
It may not sound as thrilling as conjuring a digital Einstein, but it’s how we’ll get tangible value.
Anthropic and its peers can choose to recognize this and lead the way—or cling to the superintelligence mythos and risk being leapfrogged by more pragmatic players. Personally, I hope they choose the former. I’d love to see Anthropic, for example, double down on making Claude the best damn assistant it can be given fixed intelligence. Make it the AI that never forgets what you tell it, that automatically brings in relevant documents when needed, that knows how to use a wide range of tools out of the box, and that can coordinate subtasks among multiple copies of itself seamlessly. That would genuinely move the needle for users – and they’d pay handsomely for it, too.
I don’t care if it scores a few more points on an academic benchmark; I care if it can save me an hour of debugging by recalling a conversation from two weeks ago.
In closing, let’s drop the hubris of chasing an imaginary god-level AI and focus on augmenting the very real (and very impressive) AI we already have with context, memory, and wise guidance. The firms that do so will unlock the next wave of productivity – and those that don’t will be left pitching fairy tales. The bubble of hype may well pop, but what remains will be a more grounded industry focused on solving real problems.
Informative , little too long. Could've added some human touch.